Background
Variable (V), Diversity (D), and Joining (J) recombination analysis
V(D)J recombination occurs in lymphocytes when T and B cells assemble variable (V), diversity (D), and joining (J) gene segments, contributing to the generation of receptors which recognize and respond to perturbations. V(D)J recombination produces clones of unique T cell receptor (TCR) chains or B cell receptor (BCR) chains giving rise to the diverse repertoire of T and B cell populations which are imperative to adaptive immune system function1. The frequency of generated clones can be measured and explored, giving researchers a powerful view into variation, expansion, and diversity within the biological system. You can import filtered Contig Annotation CSV files2 from the 10X Genomics Cell Ranger V(D)J or multi pipeline3. If there is matching gene expression data, it can also be imported and analyzed within the same project. We recommend uploading the filtered feature barcode matrices as either the Hierarchical Data Format (H5 or HDF5)4 or Market Exchange Format (MEX)5.
Terminology
- UMI (Unique Molecular Identifier): random 10 bp nucleotide sequence that distinguishes which reads came from the same transcript.
- Barcode: the unique identifier in each droplet which usually contains reads from a single cell.
- Contig: sequence of bases from the assembly that is comprised of reads with the same barcode and UMI which align to the same transcript6.
- Complementarity-Determining Region: CDR1, CDR2, and CDR3 are important in antigen binding of a T or B cell receptor.
- CDR3 (Complementarity-Determining Region 3): CDR3 spans the V(D)J junction. There is one CDR3 nucleotide sequence for each V(D)J contig.
- Clonotype: cells derived from a common ancestor during clonopoiesis which have a particular composition. The cells in a clonotype can have a different number of chains or different CDR3 regions but still be considered a single clone (CDR3 is a highly variable region used for binding; an example of different CDR3 regions would be from affinity maturation which can occur in memory B cells).
Understanding Clone Composition
Multiple cells can have the same clonotype and each clonotype can have multiple makeups. Each clonotype contains one or more chains (TRA and TRB for T cells and IGH, IGK and IGL for B cells), the highest scoring V, D, and J gene segments, and CDR3 nucleotide sequence. T cells have a TRA and TRB chain with V, D, J and C regions. In B cells, IGH is the heavy chain which has a V, D, and J region while IGK and IGL are the light chains with a V and J region. The Immunoglobulins have two identical heavy chains and two identical light chains. B cell isotypes are antigenic determinants that characterize the classes and subclasses of heavy chains and types and subtypes of light chains; the constant region (C gene) produced by the B cell changes but the V regions and specificity do not. Constant regions do not participate in antigen recognition, instead C regions interact to mediate biological function; so isotypes have different function but can bind the same antigen.
Import Data
- Create a new project to upload your data. Ensure that you have transferred the filtered contig_annotations.csv file(s)2 for each sample from either the cellranger vdj7 or cellranger multi8 pipeline to the server, as well as the filtered feature barcode matrices in H54 or MEX5 format from the cellranger multi pipeline for each sample if you have matching gene expression data.
- Click Import, then select Import single cell V(D)J data
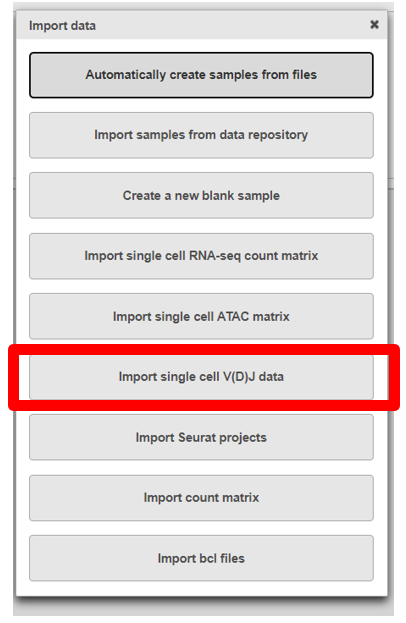
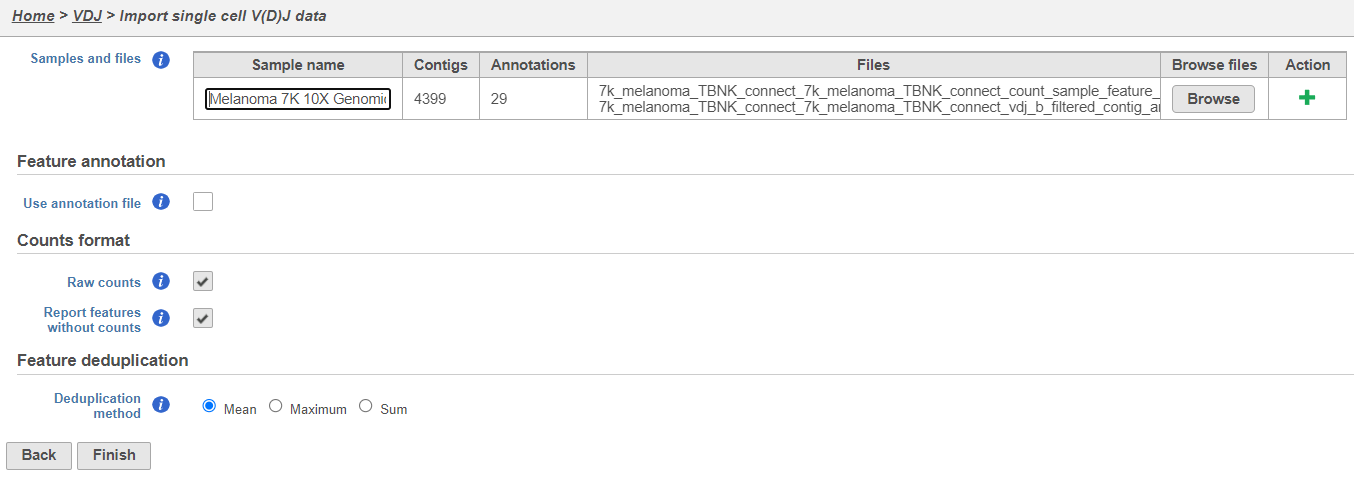
- Upload either the filtered contig_annotations.csv file alone or, if you have matching gene expression, with the filtered count matrix per sample and give each sample a name. To add a sample use the the
 Action. In the example below using default settings, there is one sample with two files, one for V(D)J and one for gene expression. Click Finish.
Action. In the example below using default settings, there is one sample with two files, one for V(D)J and one for gene expression. Click Finish.
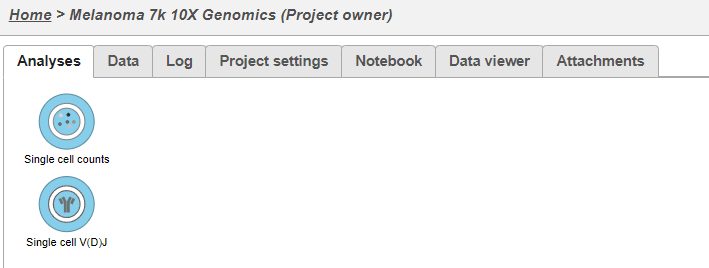
- This results in two starting nodes, one for single cell counts and one for single cell V(D)J as shown below. Note that once subsequent tasks are performed on a node, no more data can be imported into this project. The single cell counts node can be processed as usual; for help related to this please see the tutorial for Analyzing Single Cell RNA-Seq Data.
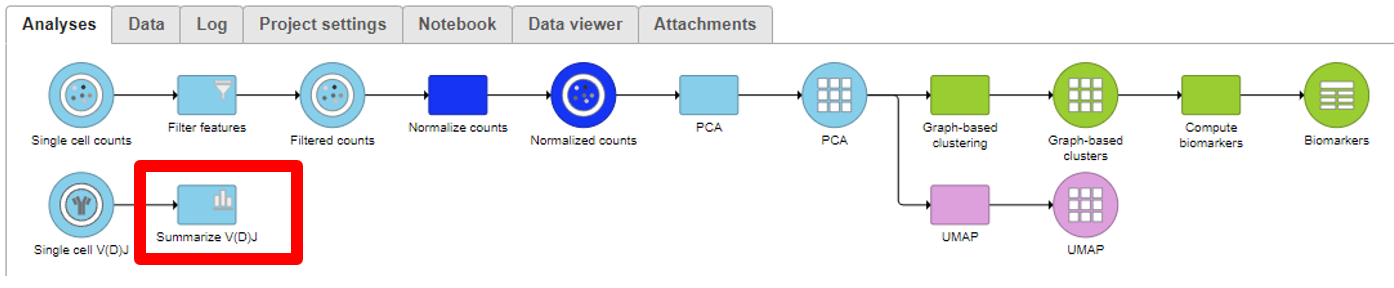
Analyzing the Single cell V(D)J node
Summarize V(D)J
- Under QA/QC tasks is the Summarize V(D)J task which will summarize the V(D)J contents by Sample name, # Cells, Barcode count, Clonotypes, Variable genes, Diversity genes, Joining genes, and Constant genes.

- Double-click on the completed task to view the contents which can be downloaded.
Clonotype Frequency Plot
Under Exploratory Analysis tasks is the Clonotype Frequency Plot task which will summarize the V(D)J node into plots of interest in the Data Viewer. Similar manual comparisons can be made in the Data Viewer. These may include determining the T cell receptor and B cell receptor chains that make up clonotypes in the samples, quantifying the clone diversity by frequency, comparing the immune repertoire between samples, and visualizing clones and gene expression data together on scatterplots like a UMAP.
- The example below shows the results from the Clonotype Frequency Plot task which is accessed by choosing to perform this task from the Single cell V(D)J node then modified in the data viewer. In this case, the barcode frequency is the number of clonotypes per cell because the barcode usually represents a single cell, so there are two cells which have clonotype5 (purple bar with information from hovering) and clonotype 5 is made of two compositions (a frequency of four for clonotype5 from the V(D)J node) witnessed by the Chain, V gene, D gene, and J gene seen below the bars and by hovering.
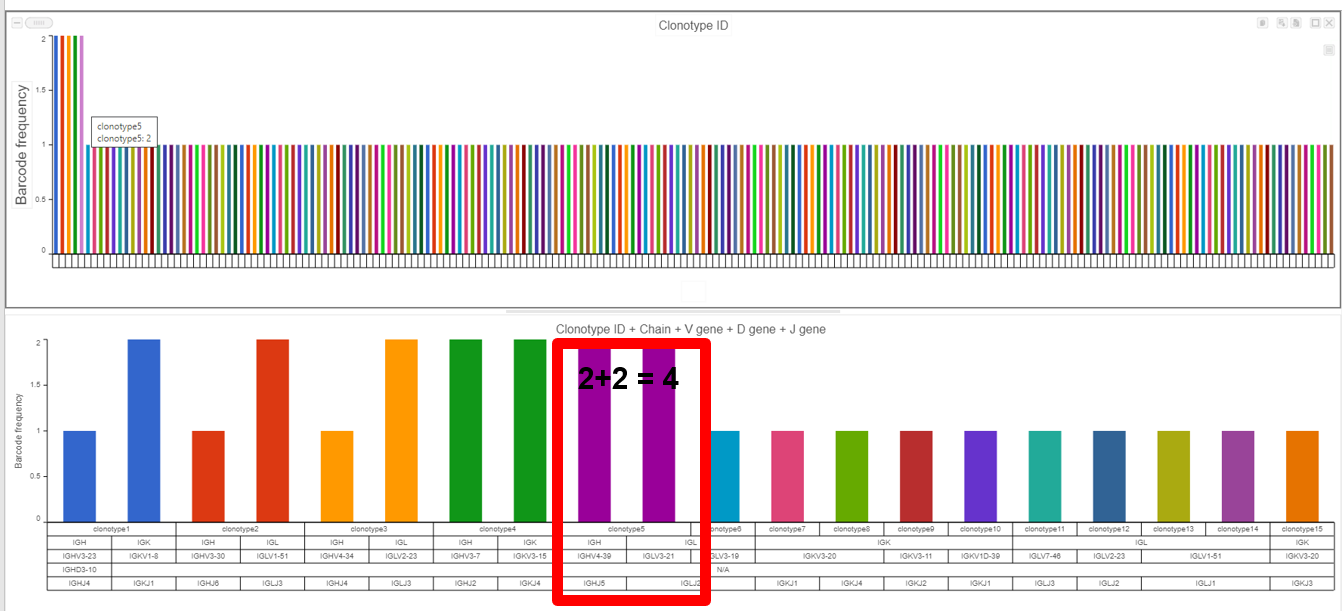
- Plotting Clonotype ID frequency, as seen below, for the gene expression node (Cell counts as the top bar chart) and VDJ node (VDJ counts as the bottom bar chart), highlights the difference between the two nodes (where the top plot is the number of cells per clonotype and the bottom plot is the number of V(D)J clonotypes present). Note that Cell Ranger does not always call the barcode as a cell and this can affect these frequencies when making comparisons between cell frequency per clonotype and barcode frequency per clonotype (an example of this would be clonotype1 when comparing the figure above and below).

Tips for Figure Making
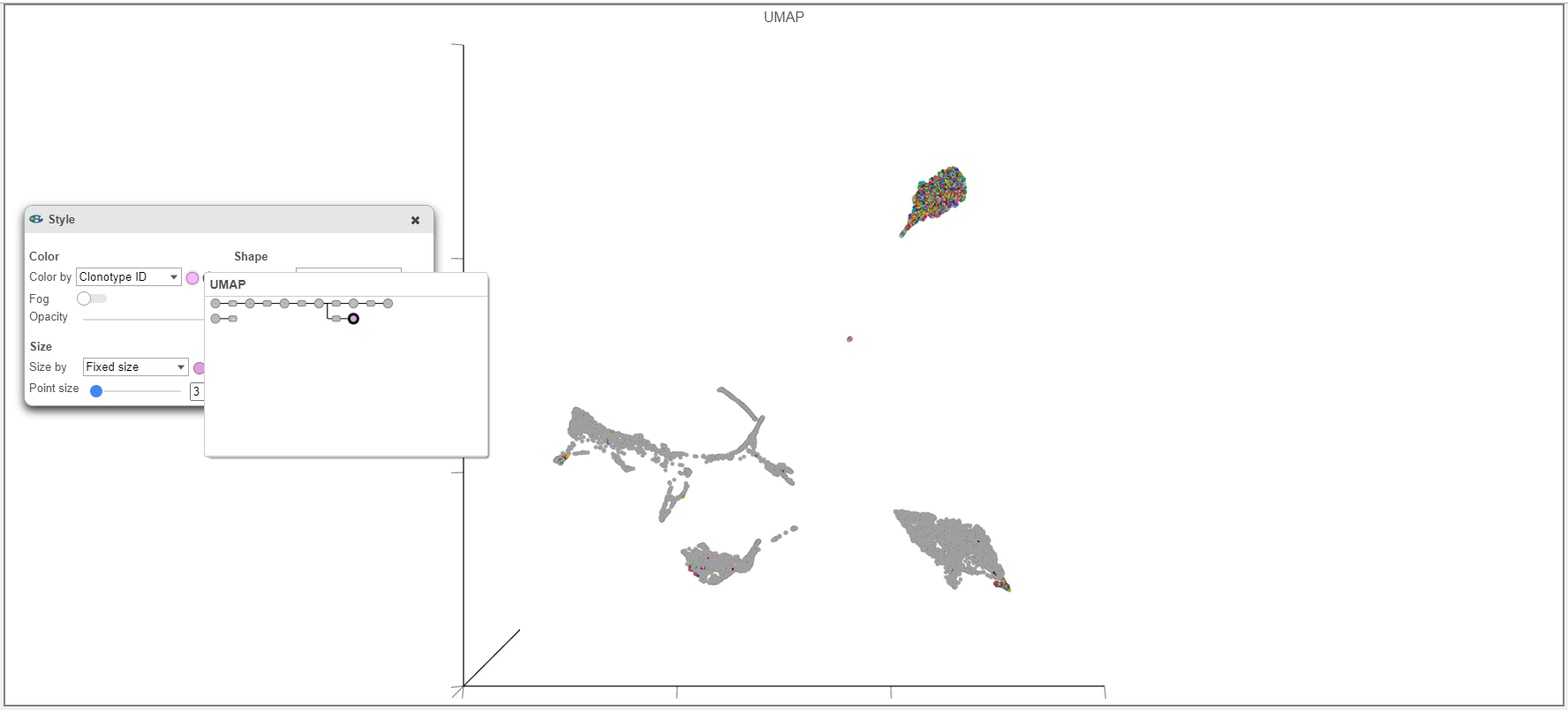
- When overlaying the Clonotype ID on plots from the Single cell counts analysis pipeline (such as the UMAP example below), make sure that the Clonotype ID from the Single cell counts node and not the VDJ node is used.
- B cell isotypes are defined by Chain and C gene. In the example below, Chain and C gene are plotted by Barcode frequency. On the left, no selection and filtering has been performed. On the plot on the right, the heavy chain has been selected and filtered by in the data. By using select & filter, criteria can be selected and focused on.


- In the left plot below, CDR3 abundance is plotted by barcode frequency and colored by Clonotype ID. In the example on the right, the plot is instead colored by Chain and other modifications have been made such as axis ticks and the number of groups per page. Note that the predicted CDR3 amino acid sequence is plotted here, but the predicted CDR3 nucleotide sequence (cdr3_nt) as well as information for other Complementarity-Determining Regions is also available.


- In the plot on the left below, barcode frequency for V genes is sorted by frequency in descending order and colored by Chain. The transposed plot on the right shows all of the groups sorted by ascending value and the heavy chain has been excluded. Gene usage plots for the D and J genes can be quickly shown by changing the data dropdown.


References
- Tonegawa, S. Somatic generation of antibody diversity. Nature 302,575–581 (1983). https://doi.org/10.1038/302575a0
- https://support.10xgenomics.com/single-cell-vdj/software/pipelines/latest/output/annotation#contig-annotation
- https://support.10xgenomics.com/single-cell-vdj/software/overview/welcome
- https://support.10xgenomics.com/single-cell-gene-expression/software/pipelines/7.0/advanced/h5_matrices
- https://support.10xgenomics.com/single-cell-gene-expression/software/pipelines/7.0/output/matrices
- https://support.10xgenomics.com/single-cell-vdj/software/pipelines/latest/algorithms/annotation#productive
- https://support.10xgenomics.com/single-cell-vdj/software/pipelines/latest/using/vdj
- https://support.10xgenomics.com/single-cell-vdj/software/pipelines/latest/using/multi
Overview
Content Tools