Page History
...
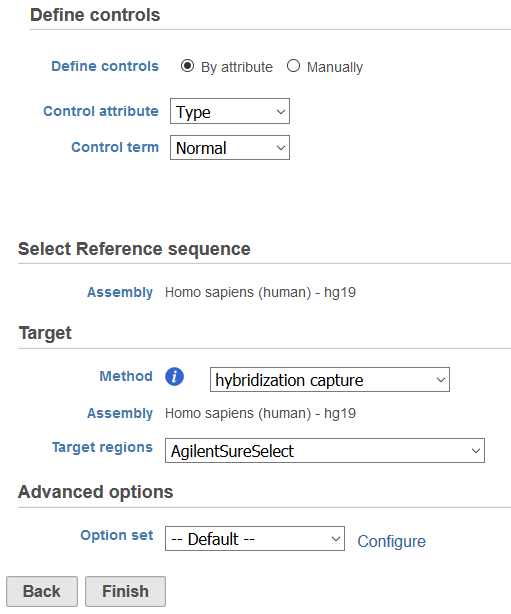
The CNVkit task can be found under the Copy number analysis tab in the context sensitive menu when any Aligned reads or Filtered reads data node is selected. The dialog consists of three sections: Define controls, Select Reference Assembly, Target, and Advanced options (Figure 1).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
...
The Target section allows for the selection of Method, where the type of sequencing experiment can by specified. While CNVkit is optimized for copy number detection in hybrid capture experiments, it can also analyze whole genome and amplicon sequencing data. Assembly should match the reference sequence previously specified. For hybrid capture or amplicon experiments, Target regions should relate to the regions sequenced in this study using a Gene/feature annotation file. For whole genome data, Annotation will specify a Gene/feature annotation file that will be used to annotate regions of copy number imbalance. The Gene/feature annotation can be previously associated with Partek® Flow® via Library File Management or added on the fly.
Advanced options allows for customization of parameters for CNV detection. Please refer to the CNVkit documentation (https://cnvkit.readthedocs.io/en/stable/) for details on the available parameters.
CNVkit report
Selecting the Task report for the Copy number data node will provide a table with test samples in the project (non-control) and the number of copy number regions associated with each sample (Figure 2). Selecting Option columns at the top right of the table will allow for attribute columns to be added to the report.
Selecting a sample in the table will open the sample-specific CNVkit report (Figure 3). The sample table will provide a row for each detected region of copy number imbalance in the data with Chromosome, Start and End coordinates. The table also includes the following information:
- gene: content in the copy number region as defined by the associated Target regions or Annotation file
- log2: pileup height at peak summit
- depth: negative log10 pvalue for the peak summit
- probes: fold enrichment for the peak summit against random Poisson distribution with local lambda
- weight: negative log10 qvalue at peak summit
| Additional assistance |
|---|
|
| Rate Macro | ||
|---|---|---|
|
Overview
Content Tools