Page History
...
There are many useful visualizations, annotations, and biological interpretation tools that can operate on a gene list. In order for these features work with an imported list, an annotation file must be associated with the gene list. Additionally, many operations that work with a list of significant genes (like GO- or Pathway-Enrichment) require comparison against a background of “non-significant” genes. The quickest way to accomplish both is to use the background of “all genes” for that organism provided by an annotation source like RefSeq, Ensembl, etc. in .pannot (Partek® annotationPartek annotation), .gff, .gtf, .bed, tab- or comma-delimited format. If the file is not already in a tab-separated or comma delimited format, you may import, modify, and save the file in the proper file format.
...
- Select the annotation file; we have selected in this example, we select a .pannot file downloaded from Partek distributed library file repository – hg19_refseq_14_01_03_v2.pannot from the C:/Microarry Libraries folder
- Delete or rearrange the columns as necessary; we have placed the column with identifiers (should be unique ID) that correspond to our gene list first
- Select File then Save As Text File... to save the annotation file; we have named it Annotation File (Figure 2)
...
This brings up the Configure Genomic Properties dialog (Figure 3).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

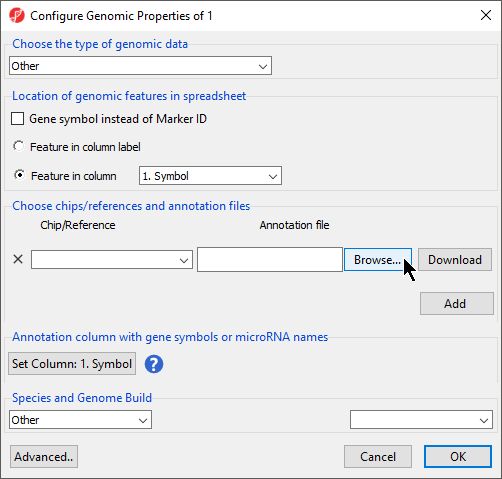
- Select Browse under Annotation File
- Choose the annotation file; we have chosen Annotation File.txt
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
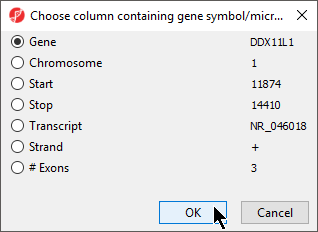
- Select the appropriate column; here the default choice of 1. Symbol is appropriate
- Select OK to return to the Configure Genomic Properties dialog
- Select the appropriate species and genome build options; we have selected Homo sapiens and hg19 (Figure 6)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

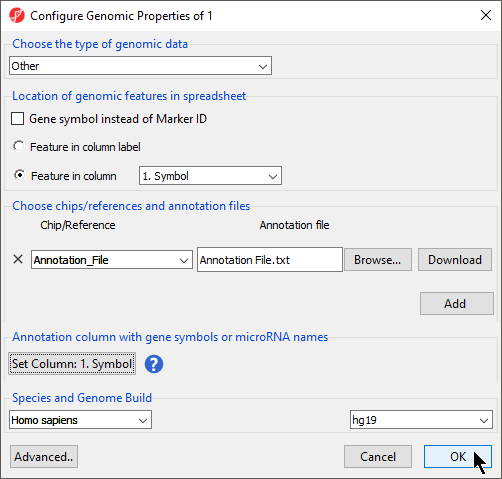
- Select OK
- Select (
 ) to save the spreadsheet
) to save the spreadsheet
The annotation file has been associated with the spreadsheet and additional tasks can now be performed on the data, e.g. since the annotation has genomic location, you can draw chromosome view on this data.
Adding annotations to a spreadsheet
...
If an annotation file has been associated with a spreadsheet, annotations from the file can be added as columns in the spreadsheet when each identifier is on a row.
- Right click on a column header
- Select Insert Annotation
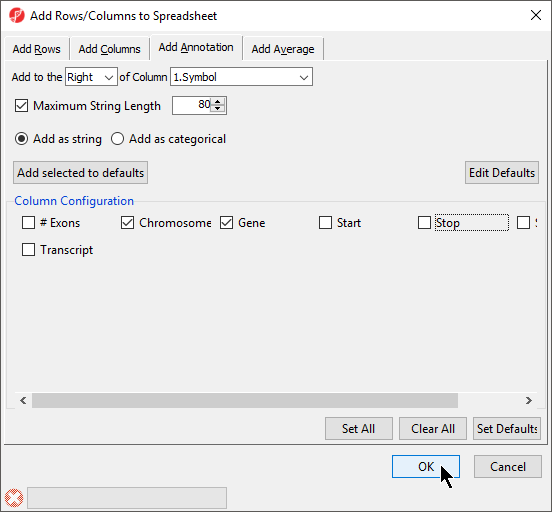
- Select columns to add from Column Configuration; we have selected Chromosome, Start, and Stop (Figure 7)
- Select OK
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
Annotating with cytobands
- Select Annotate with Cytobands from Tools in the main toolbar when a suitable spreadsheet is open
A column with cytoband locations will be added to the spreadsheet. Adding a cytoband is possible if genomic coordinates are associated with the gene list spreadsheet.
Annotating with known SNPs
- Select Annotate with Known SNPs... from Tools in the main toolbar when a suitable spreadsheet is open
A column of SNPs associated the listed genes and a column indicating the number of SNPs known to be associated with the genes will be added to the spreadsheet. If a SNP database has not been previously downloaded, it will need to be downloaded through the SNP database dialog (Figure 8).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Alternatively, to generate a list of SNP IDs per row, right-click on a row header and select Create list of dbSNP.
In addition to SNPs, this feature can associate any data with a list of genes or genomic coordinates; the dbSNP database, any miRNA database, data from the Database of Genomic Variants (dgv), any mRNA transcriptome database, or any custom annotation source can be associated with your list. In each case, this feature will add columns to the imported gene list spreadsheet that match the genes with features from those databases.
| Page Turner | ||
|---|---|---|
|
| Additional assistance |
|---|
| Rate Macro | ||
|---|---|---|
|
...
Overview
Content Tools