Differential expression analysis can be used to compare cell types. Here, we will compare glioma and oligodendrocyte cells to identify genes differentially regulated in glioma cells from the Oligodendroglioma subtype. This comparison is of interest because glioma cells in Oligodendroglioma are thought to originate from oligodendrocytes.
Filter samples
To analyze only the Oligodendroglioma subtype, we can filter the samples.
- Click the green Classified groups data node
- Click Filtering in the task menu
- Click Filter samples (Figure 1)
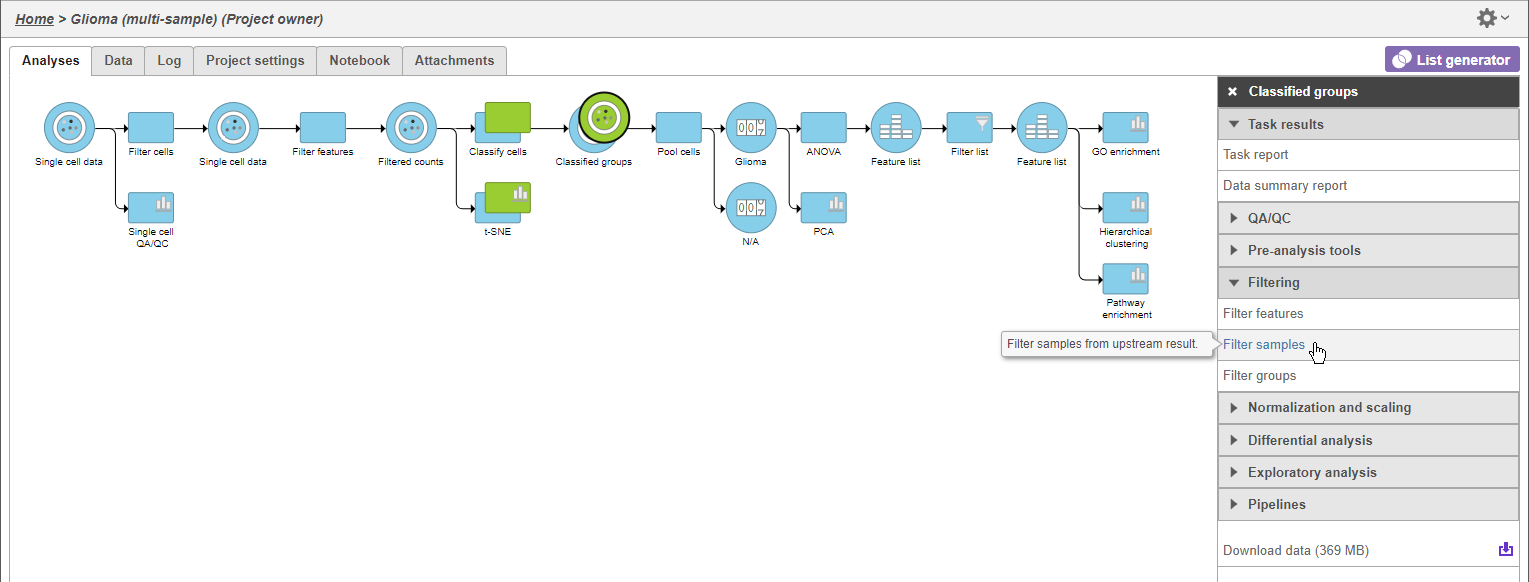
Figure 1. Invoking the sample filter
The filter lets us include or exclude samples based on sample ID and attribute (Figure 2).
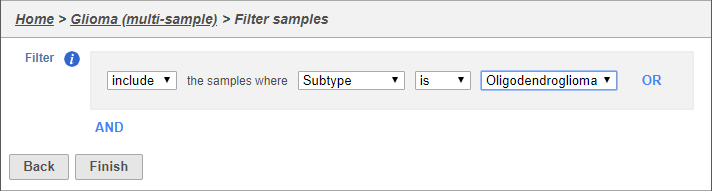 Figure 2. Configuring the sample filter
Figure 2. Configuring the sample filter
- Set the filter to Include samples where Subtype is Oligodendroglioma
- Click Finish to apply the filter
A Filtered Counts data node will be created with only cells that are from Oligodendroglioma samples (Figure 3).
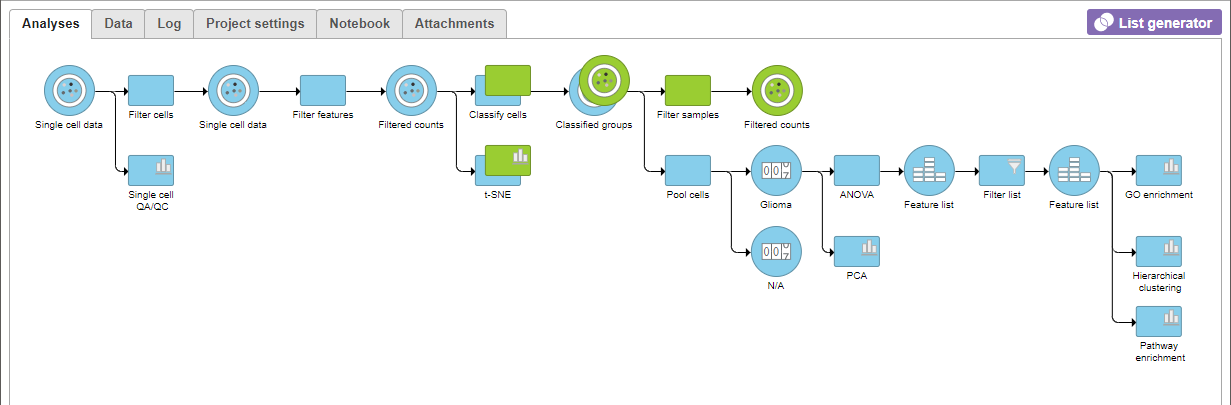 Figure 3. Filter samples generates a Filtered counts data node
Figure 3. Filter samples generates a Filtered counts data node
Filtering groups
Because we are only interested in analyzing glioma and oligodendrocyte cells, we will filter out microglia cells using the groups filer.
- Click the green Filtered counts data node
- Click Filtering in the task menu
- Click Filter groups
This filter lets us include or exclude cells based on classifications or other cell-level attributes.
- Set the filter to Exclude groups where Classification is Microglia (Figure 4)
- Click Finish to apply the filter
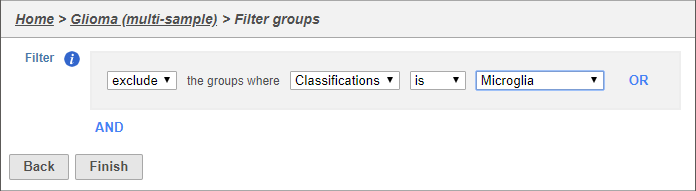
Figure 4. Filtering groups of cells
A Filtered Counts data node will be created with only glioma and oligodendrocyte cells from the Oligodendroglioma samples. The Filtered groups task must complete before we can proceed to identifying differentially expressed genes.
Identify differentially expressed genes
- Click the second green Filtered counts data node
- Click Differential analysis in the task menu
- Click ANOVA (Figure 5)
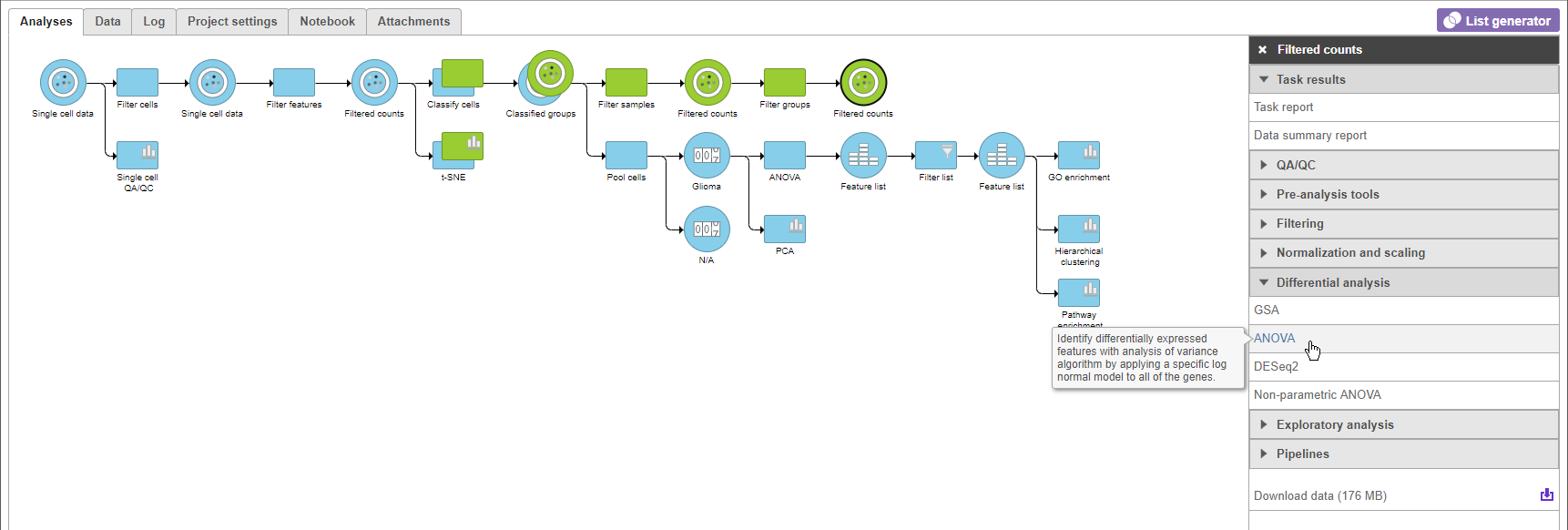 Figure 5. Invoking ANOVA
The configuration options (Figure 6) include cell-level attributes. Here, we want to compare different cell types so we will include Classification.
Figure 5. Invoking ANOVA
The configuration options (Figure 6) include cell-level attributes. Here, we want to compare different cell types so we will include Classification.
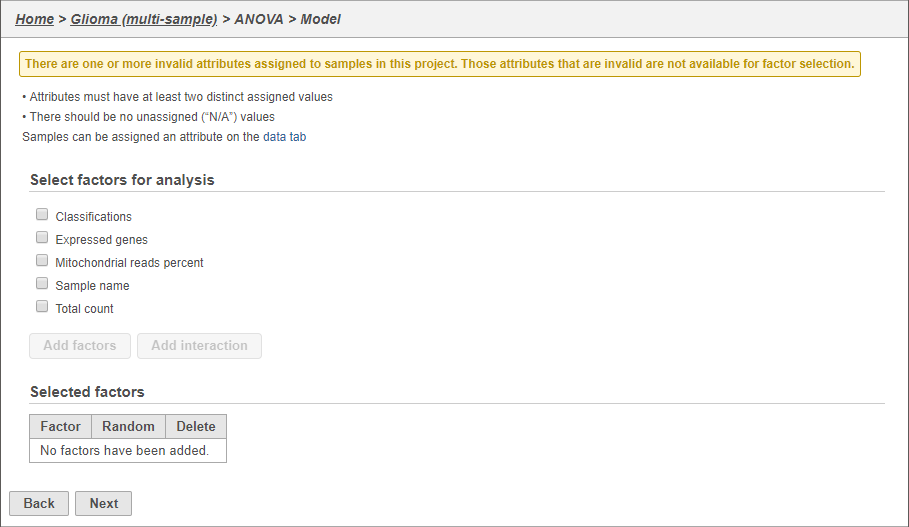 Figure 6. Configuring the ANOVA model
Figure 6. Configuring the ANOVA model
- Click Classification
- Click Add factors
- Click Next
Next, we will set up a comparison between gliioma and oligodendrocytes.
- Click Glioma
- Click the arrow to move it to the top-right panel
- Click Oligodendrocytes
- Click the arrow to move it to the top-right bottom-right panel
- Click Add comparison (Figure 8)
This will set up fold calculations with glioma as the numerator and oligodendrocytes as the denominator.
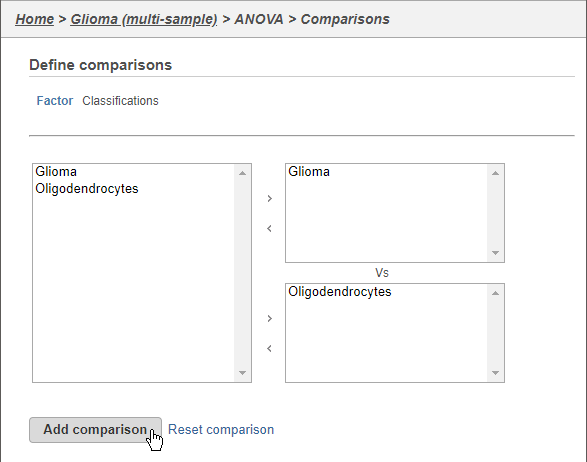 Figure 7. Defining the comparison between Glioma and Oligodendrocytes
Figure 7. Defining the comparison between Glioma and Oligodendrocytes
- Click None in the Read count normalization section
- Click Finish to run the ANOVA
A green Feature list node will be generated containing the results of the ANOVA.
- Double-click the green Feature list node to open the ANOVA report
Because of the large number of cells and large differences between cell types, the p-values and FDR step up values are very low for highly significant genes.
- Click
 to view the Volcano plot
to view the Volcano plot - Choose FDR step up from the Y axis source drop-down menu
- Set the X axis significance thresold to 10
- Set the Y axis significance thresold to 0.001
This gives 132 up-regulated and 159 down-regulated genes (Figure 9).
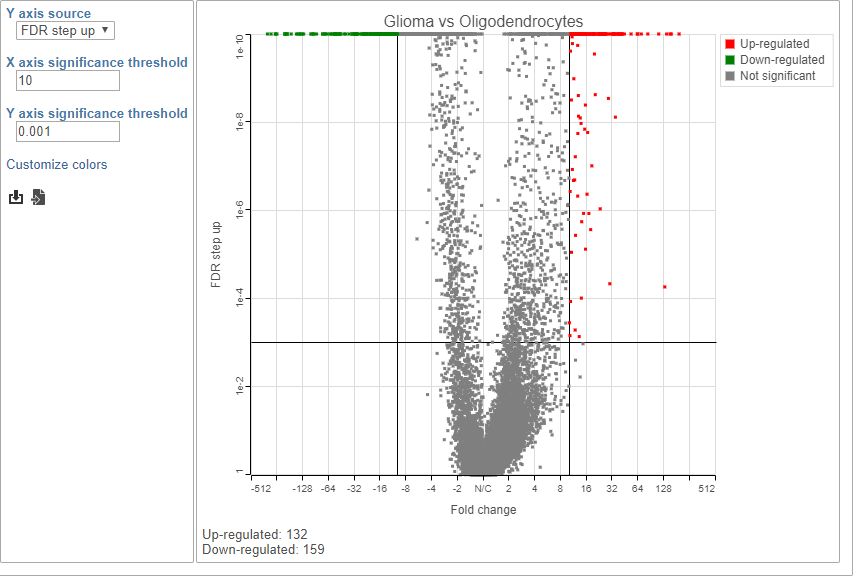
Figure 8. Previewing a filter by adjusting the significance thresholds
We can now recreate these conditions in the ANOVA report filter.
- Click ANOVA report at the top of the screen to return to the ANOVA report
- Click FDR step up
- Set the FDR step up filter to Less than or equal to 0.001
- Click Fold change
- Set the Fold change filter to From -10 to 10
The filter should include 291 genes.
- Click
 to apply the filter and generate a filtered Feature list node
to apply the filter and generate a filtered Feature list node
To visualize the results, we can generate a hierarchical clustering heat map.
- Click the second green Feature list
- Click Exploratory analysis in the task menu
- Click Hiearchical clustering
Using the hierarchical clustering options we can choose to include only cells from certain samples. We can also choose the order of cells on the heat map instead of clustering. Here, we will include only glioma cells and order the samples by sample ID (Figure 10).
- Uncheck Cluster samples
- Click Filtering and set the filter to include Classifications is Glioma
- Choose Sample name from the Sample order drop-down menu in the Ordering section
- Click Finish
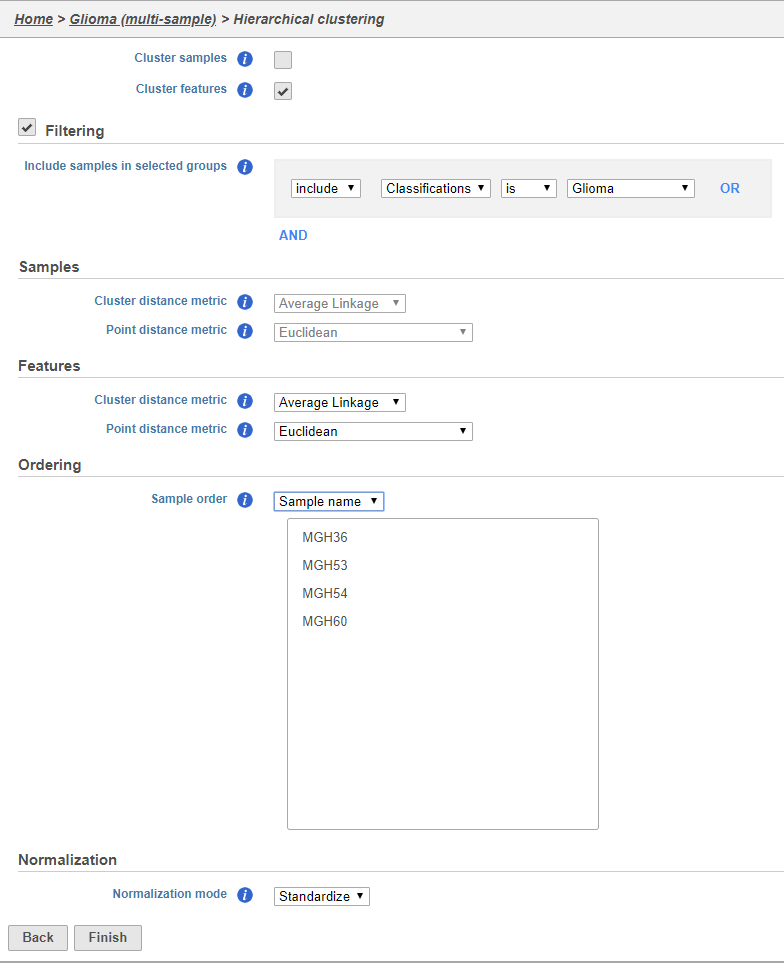
Figure 9. Configuring hierarchical clustering
- Double click the green Hierarchical clustering node to open the heat map
The heat map will appear black at first; the range from red to green with a black midpoint is set very wide because of a few outlier cells. We can adjust the range to make more subtle differences visible.
- Set Low to -2
- Set High to 2
The heat map now shows clear patterns of red and green.
- Select Sample name from the Attributes drop-down menu
Cells are now labeled with their sample name. Interestingly, samples show characteristic patterns of expression (Figure 11).
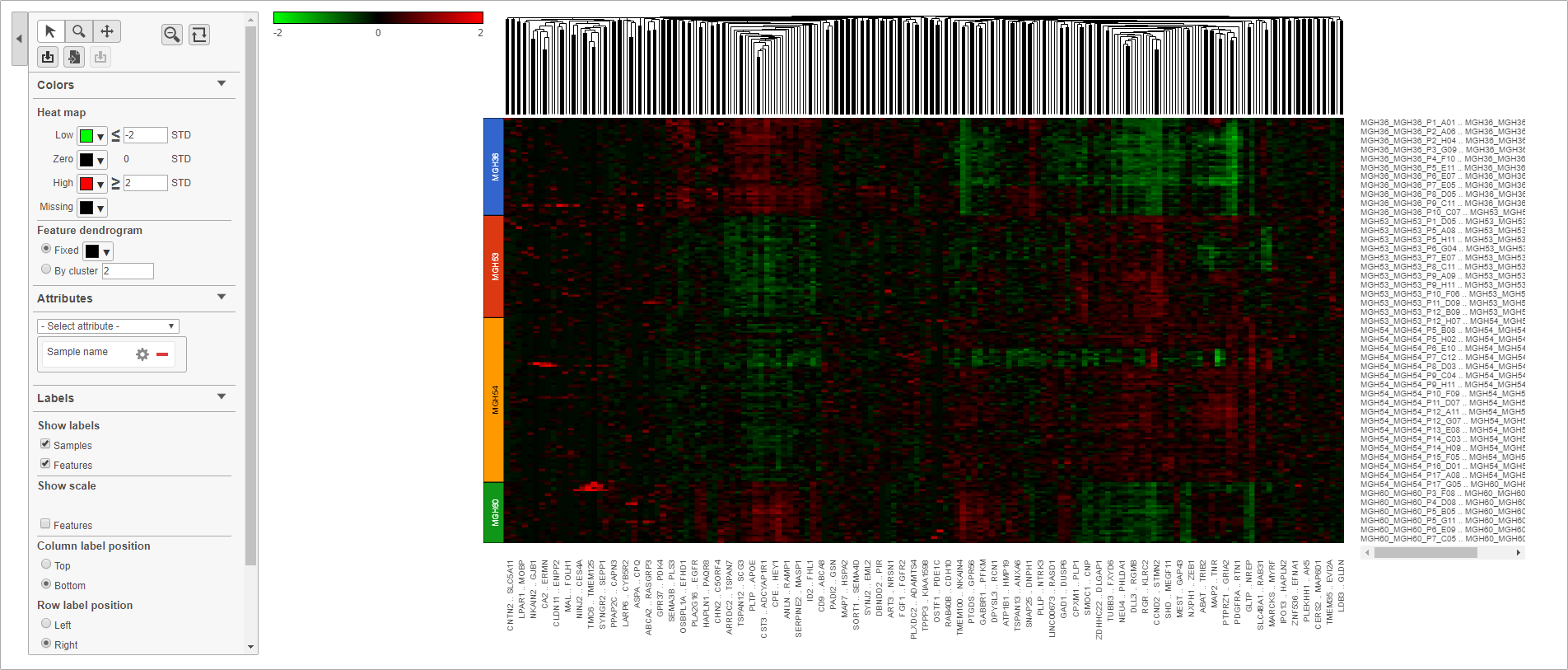
Figure 10. Hierarchical clustering heat map with cells on rows (ordered by sample name) and genes on columns (clustered)
- Click Glioma (multi-sample) to return to the pipeline view
We can use GO enrichment to futher characterize the differences between glioma and oligodendrocyte cells.
- Click the second green Feature list node
- Click Biological interpretation in the task menu
- Click Enrichment anlaysis (Figure 12)
Figure 11. Invoking Enrichment analysis
- Choose Homo sapiens (human) - hg38 from the Assembly drop-down menu
- Select Finish to continue with the most recentgene set
A GO enrichment node will be added to the pipeline view (Figure 13).
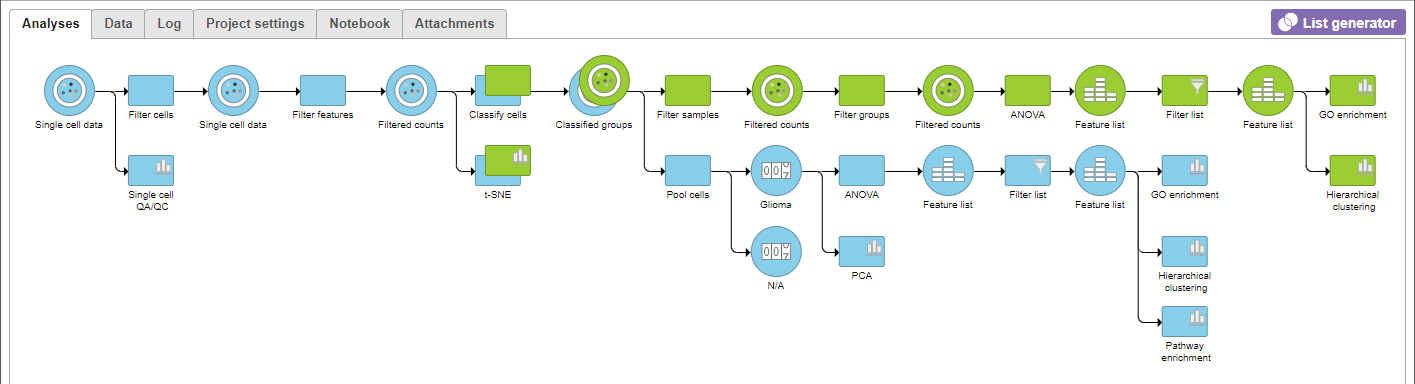
Figure 12. Completed tutorial analysis pipeline
- Double-click the green GO enrichment task node to open the task report
Top GO terms in the enrichment report include "myelin sheath", "ensheathment of neurons", and "axon ensheathment" (Figure 14), which corresponds well with the role of oligodendrocytes in creating the myelin sheath that supports and protect axons in the central nervous system.
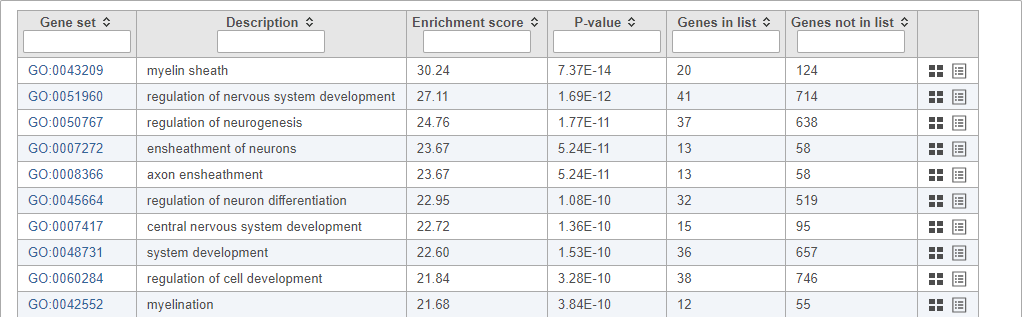 Figure 13. GO enrichment task report
Figure 13. GO enrichment task report
Additional Assistance
If you need additional assistance, please visit our support page to submit a help ticket or find phone numbers for regional support.


| Your Rating: |
|
Results: |

|
8 | rates |
Overview
Content Tools