This task can be invoke from count matrix data node or clustering task report, it performs t-Tests on selected attribute, comparing every group vs other for each subgroup and select the up-regulated genes as biomarker.
Computer biomarker dialog
In the dialog, select attribute. The available attributes are categorical attributes can be seen on the data node which includes project level attributes and data node local annotation--e.g. graph-based cluster result (Figure 1). If the task is run on graph-based clustering output data node, the calculation is using upstream data node which contains feature count – typically the input data node of PCA.
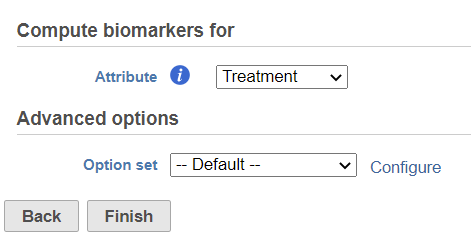
Figure 1. Compute biomarker dialog: selecting attribute
Click on the Configure of Advanced option to change the criteria on output features (Figure 2).

Figure 2. Configure the biomarker filter criteria based on fold change
By default, the result outputs features that are up-regulated at least 1.5 fold change (in linear scale) for each subgroup comparing to others. The result is displayed in a table with each column is a subgroup name, each row is a feature.
Additional Assistance
If you need additional assistance, please visit our support page to submit a help ticket or find phone numbers for regional support.


| Your Rating: |
|
Results: |

|
2 | rates |
Overview
Content Tools