Join us for a webinar: The complexities of spatial multiomics unraveled
May 2
Page History
...
Each combination of sequencing instrument and sequencing protocol varies in terms of how precisely it is able to estimate the transcript abundance, and/or what data biases it propagates downstream. A good quantification algorithm is expected to extract the maximal amount of information from the reads, and, importantly, to adjust for the biases of the sequencer and protocol. However, the practical impact of biases depends on the purpose of the study. Likewise, if the study agenda includes some particular items such as novel transcript discovery, this alone can determine the choice of a combination of aligner and quantification package.
Challenges and Solutions
The most recognized quantification issues common to RNA-Seq include the following:
...
- Sequence (composition) bias
- Position bias
- GC bias
Multireads
Multireads (or multimappers) are reads aligning to multiple locations in the genome. Three different approaches to handling those reads have been described.
...
For paired-end reads with multiple alignments, it is possible to improve quantification by extracting information from the fragment (insert) size distribution. This feature is available in Cufflinks.
Sequence Bias
Sequence bias refers to the observation that the reads that have particular subsequences of nucleotides (typically, at 5’ or 3’ end) may be over- or underrepresented due to some artifacts of sequencing technology (8, 9) (for an illustration see Figure 2 in Roberts et al. (4)). The corresponding bias correction is implemented in Cufflinks.
Position Bias
Position bias (10 - 12) is manifested in unequal distribution of reads along the length of a transcript (see Figure 4 in Jiang et al. (12)). The corresponding correction is implemented in Cufflinks.
GC Bias
GC bias means that the estimated abundance of a transcript (gene) is dependent on its GC content. While Dohm et al. reported that GC-rich regions attract reads (see Figure 2 in (13)), another study argued that the dependence can go either way (see Figure 2 in Zheng et al. (14)). Although there is no available package that contains the GC bias correction Cufflinks team shown that in some cases the GC bias is highly correlated with the sequence bias and then a separate GC correction is unnecessary.
Assessing the Practical Impact of Biases
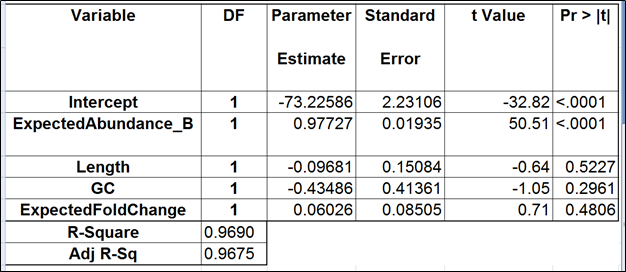
An accepted way to measure the impact of a certain bias is as follows: take a number of transcripts (genes) and perform the quantification with and without bias correction and then observe the change in concordance between the expected (known) and the estimated abundance. Initially, the expected abundances were estimated based on qPCR (4). More recently, the usage of presumably more accurate External RNA Controls Consortium (ERCC) controls took hold (12, 15). In the latter approach, the known abundance is measured as concentration of transcripts in attomoles/μL.
...
On the other hand, suppose we want to compare the expression of two isoforms that differ by a short subsequence, such as a 50 bp exon. Then, the GC bias can be practically significant because the difference in expression may be attributed to the exon’s GC content. Likewise, it may be attributed to the nucleotide composition of the exon that causes it to attract an unfair number of reads due to the sequence bias. In that case, the GC and sequence biases need to be adjusted for during quantification.
Partek EM Algorithm: Validation of Quantification Results
Data from the Sequencing Quality Control Project (SEQC) was obtained from the Mayo Clinic site, which used the Illumina HiSeq2000. The dataset consists of about one billion of 2×100 paired-end reads, which amounts to about 512 GB of uncompressed fastq files, with about 4 GB for each of the 128 samples.
...
| Numbered figure captions | ||||||
|---|---|---|---|---|---|---|
| ||||||
|
| Numbered figure captions | ||||||
|---|---|---|---|---|---|---|
| ||||||
|
Conclusions
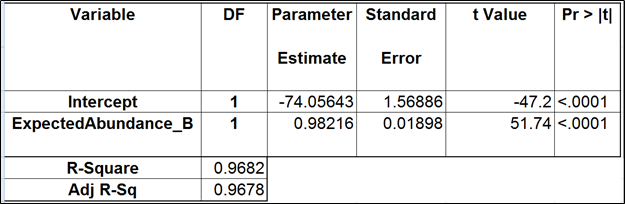
Although we did not report the results obtained by Cufflinks quantification algorithm, we believe that no extra analysis is necessary. First, the nature of ERCC approach does not make it a tool sensitive enough to detect the subtle effects that are estimated by Cufflinks quantification algorithm. Second, we showed that, even if those effects were taken into account, there would be very little room for improvement that could be detected by ERCC tools.
Jiang and colleagues came to a similar conclusion (12). Although they did not include the dose response and fold change plots in their manuscript, in personal correspondence they acknowledged that they had actually constructed the plots but failed to see a significant impact of the bias corrections implemented in Cufflinks. The minimal ERCC transcript length is about 250 bp, and, unless one interested in comparing isoforms that differ by a much shorter sequence (50 bp is a good estimate), the bias corrections are of little use.
References
Langmead B, Hansen KD, Leek JT. Cloud-scale RNA-sequencing differential expression analysis with Myrna. Genome Biol. 2010;11(8):R83.
Li J, Jiang H, Wong WH. Modeling non-uniformity in short-read rates in RNA-Seq data. Genome Biol. 2010;11:R50.
Xing Y, Yu T, Wu YN, Roy M, Kim J, Lee C. An expectation-maximization algorithm for probabilistic reconstructions of full-length isoforms from splice graphs. Nucleic Acids Res. 2006;34:3150-3160.
Roberts A, Trapnell C, Donaghey J, Rinn JL, Pachter L. Improving RNA-Seq expression estimates by correcting for fragment bias. Genome Biol. 2011;12:R22.
Trapnell C, Williams BA, Pertea G, et al. Transcript assembly and quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation. Nat Biotechnol. 2010;28:511-515.
Trapnell C, Roberts A, Goff L, et al. Differential gene and transcript expression analysis of RNA-seq experiments with TopHat and Cufflinks. Nat Protoc. 2012;7:562-578.
Roberts A, Pimentel H, Trapnell C, Pachter L. Identification of novel transcripts in annotated genomes using RNA-Seq. Bioinformatics. 2011;27:2325-2329.
Hansen KD, Brenner SE, Dudoit S. Biases in Illumina transcriptome sequencing caused by random hexamer priming. Nucleic Acids Res. 2010;38:e131.
Li J, Jiang H, Wong WH. Modeling non-uniformity in short-read rates in RNA-Seq data. Genome Biol. 2010;11:R50.
Li B, Ruotti V, Stewart RM, Thomson JA, Dewey CN. RNA-Seq gene expression estimation with read mapping uncertainty. Bioinformatics. 2010;26:493-500.
Leng N, Dawson JA, Thomson JA, et al. EBSeq: an empirical Bayes hierarchical model for inference in RNA-seq experiments. Bioinformatics. 2013;29:1035-1043.
Jiang L, Schlesinger F, Davis CA, et al. Synthetic spike-in standards for RNA-seq experiments. Genome Res. 2011;21:1543-1551.
Dohm JC, Lottaz C, Borodina T, Himmelbauer H. Substantial biases in ultra-short read data sets from high-throughput DNA sequencing. Nucleic Acids Res. 2008;36:e105.
Zheng W, Chung LM, Zhao H. Bias detection and correction in RNA-Sequencing data. BMC Bioinformatics. 2011;12:290.
ERCC RNA spike-in control mixes. http://tools.thermofisher.com/content/sfs/manuals/cms_086340.pdf Accessed: March 25, 2016
Oshlack A, Wakefield MJ. Transcript length bias in RNA-seq data confounds systems biology. Biol Direct. 2009;4:14.
...
Overview
Content Tools