Join us for a webinar: The complexities of spatial multiomics unraveled
May 2
Page History
...
The idea of scaling is to adjust the observed response, Y, so that its expectation is not dependent on X1,… Xp. If a random factor is present in the model, it describes not the expected value of Y but the variance of error term and/or correlation among observations. Technically speaking, it is impossible to use a random factor to adjust the expectation of Y and therefore we assume that all of the nuisance factors are fixedWe treat all of the nuisance factors as fixed because our primary goal is to adjust the expectation of response. However, since in some models (Poisson, Negative Binomial) the response variance is dependent on the mean, we also adjust the response variance for the batch effect whenever such models are used.
We fit a generalized linear or loglinear model with X1,… Xp as covariates to obtain the estimates of c1,… cp as follows:
...
The scaling step in Seurat [2] allows the user to choose among log-linear, Negative Binomial, and Poisson models. Unfortunately for the user, Seurat provides no guidance for as to how to pick the best option and, most likely, the log-linear default is applied all the time in practice. Likewise, if there are a few batch factors, there is no guidance in Seurat as to how to decide what design (a set of batch factors, possibly with interactions) is the best. In particular, including factors that do not exhibit a significant batch effect can lead to overcorrection meaning that the variation of interest is removed instead of the nuisance variation.
In theory, the problem of choosing the best model is tricky because, strictly speaking, the choice of best response distribution is dependent on the unknown factor Z0. That being said, it is possible to automate the model choice by utilizing the AICc exactly the way it is already implemented in Flow GSA. The multiple models are constructed by combining the available response distributions with a set of all possible batch designs up to 2nd order (subject to a hierarchical restriction). In the case of multimodel approach, the final scaled response 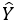 is obtained by weighting from individual models by the corresponding Akaike weights.
is obtained by weighting from individual models by the corresponding Akaike weights.
When there is more than one nuisance factor, it is also possible to leverage GSA’s ability to consider multiple first and second order designs along with multiple response distributions. However, for simplicity it might be better to restrict scaling to a first order model that includes all of the nuisance factors specified by the user.
References
[1] Risso et al, 2014, Normalization of RNA-Seq data using factor analysis
...
Overview
Content Tools