Page History
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
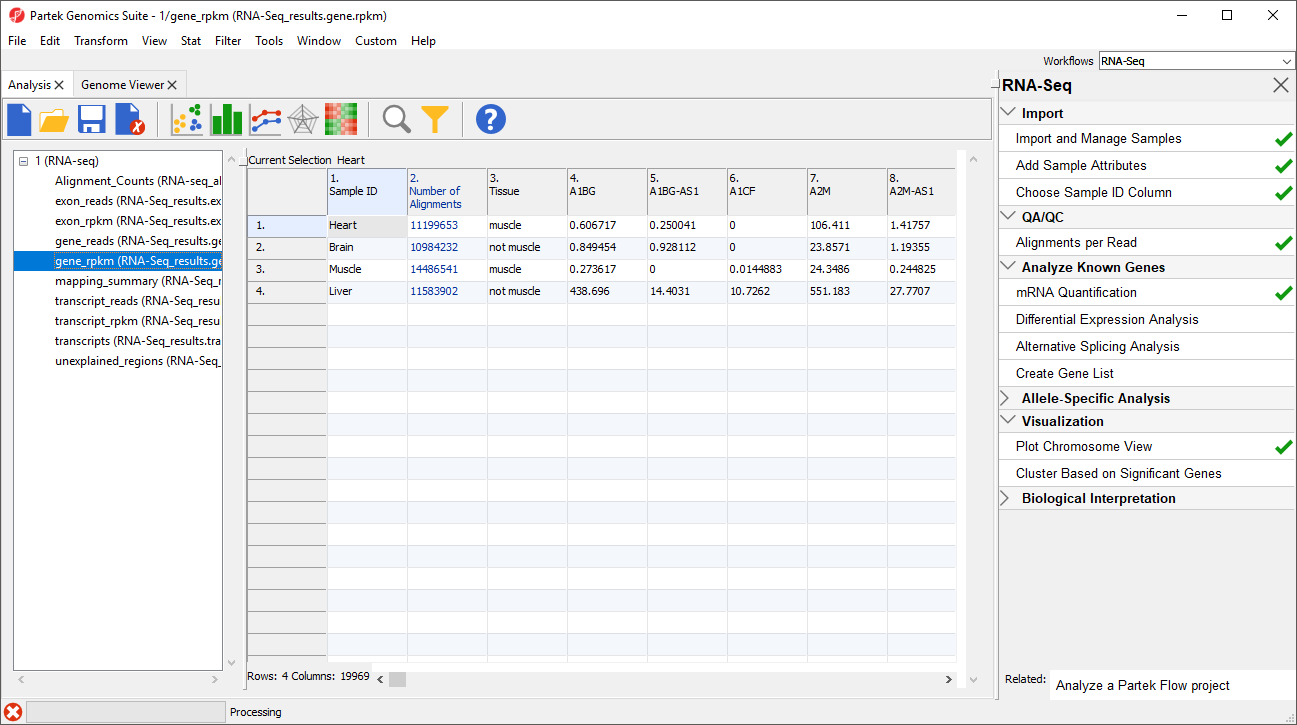
_reads and _rpkm spreadsheets
Data on features - genes, transcripts, and exons - is presented before and after normalization as _reads and _rpkm spreadsheets. In this tutorial, we have created exon_reads, exon_rpkm, gene_reads, gene_rpkm, transcript_reads, and transcript_rpkm spreadsheets.In these spreadsheets, samples are listed one per row and the normalized counts of the reads mapped to features are in columns (Figure 2).
_rpkm spreadsheets can be used to perform differential expression analysis using ANOVA. It may also be useful to view how samples group together using a PCA plotfor data analysis. Sample grouping can be visualized using PCA. Select View > Scatter Plot from the toolbar or press ![]() on the quick action bar to create a PCA plot from the selected spreadsheet. For See Exploratory Gene Expression Data Analysis for an example of using PCA plots , see Exploratory Gene Expression Data Analysis for data analysis or consult Chapter 7 of the Partek User's Manual for a detailed introduction to PCA. With replicates in a sample group, you would also be able to perform use the _rpkm perform Differential expression analysis using ANOVA.
on the quick action bar to create a PCA plot from the selected spreadsheet. For See Exploratory Gene Expression Data Analysis for an example of using PCA plots , see Exploratory Gene Expression Data Analysis for data analysis or consult Chapter 7 of the Partek User's Manual for a detailed introduction to PCA. With replicates in a sample group, you would also be able to perform use the _rpkm perform Differential expression analysis using ANOVA.
transcripts spreadsheet
The transcripts spreadsheet details the analysis results of RNA-Seq if there are no replicates. Each row lists a separate transcript.
It is possible to derive basic information about differential and alternative splicing between your samples if you don’t have replicates from the RNA-Seq_result.transcripts spreadsheet using a simple chi-squared or log-likelihood tests since each sample is represented only once and the null hypothesis is that the transcripts are evenly distributed across all samples. However, the power of Partek Genomics Suite software resides in the implementation of a mixed-model ANOVA that can handle unbalanced and incomplete datasets, nested designs, numerical and categorical variables, any number of factors, and flexible linear contrasts when you do have biological replicates.
The unexplained_regions spreadsheet
The contents of this spreadsheet are explained in more detail in a later section of the tutorial - ___.
| Page Turner | ||
|---|---|---|
|
| Additional assistance |
|---|
|
| Rate Macro | ||
|---|---|---|
|
Overview
Content Tools