Page History
Descriptive statistics task can be invoked on matrix data node e.g. gene counts, normalized counts Gene Counts, Normalized Counts data node in bulk RNA seq analysis pipeline or single cell Single Cell counts data Data node etc. It calculates measures of central tendency and variability on observations or features of the matrix data.
...
- Click on a counts data node
- Choose Descriptive Statistics in Pre-analysis tools Statistics section of the toolbox (Figure 1)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

This will invoke the dialog configuration dialog; use it to specify which calculation(s) will be performed on cells (or samples for a bulk analysis data node) or features (Figure 2).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
 |
A second data node of a different type than the first selected data node is chosen automatically. The second data node can selected manually using the Select data node button.
- Click Select data node to choose the second data node you want to merge (Figure 1)
...
| SubtitleText | Opening the data node selector |
|---|---|
| AnchorName | Picking a second node |
...
|
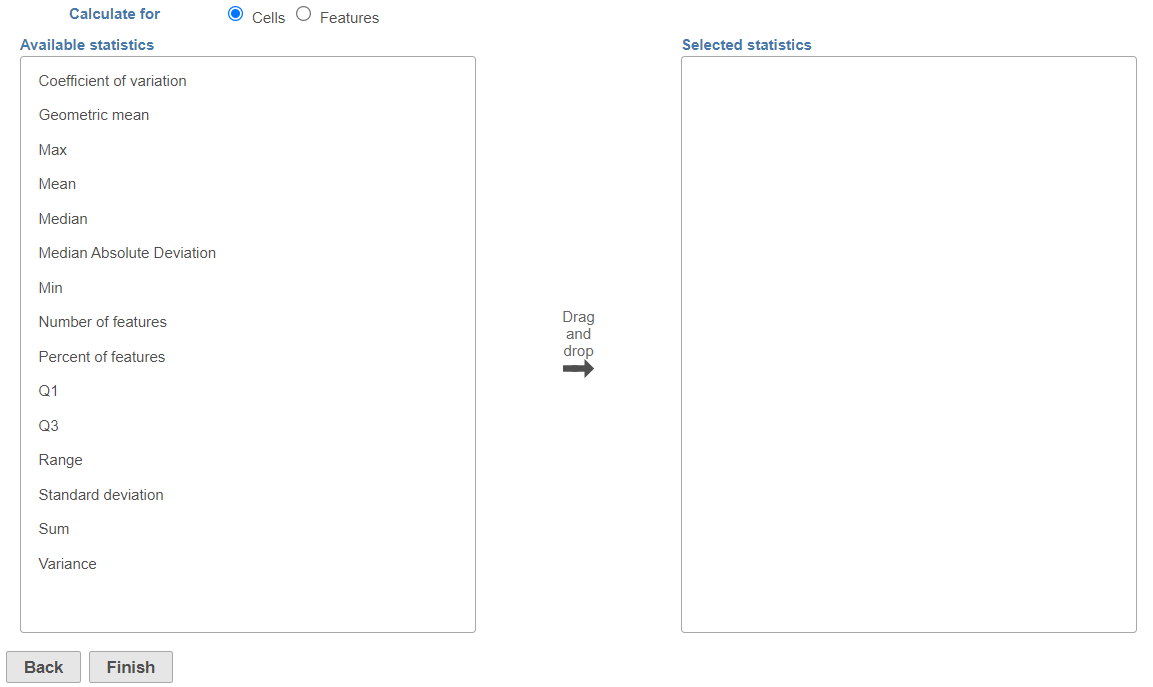
The available statistics are listed on the left panel, suppose "x1, x2, ..., xn"represent an array of numbers
- Coefficient of variation (CV):
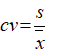 s represent the standard deviation
s represent the standard deviation - Geometric mean: g=

- Max:
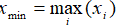
- Mean:
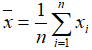
- Median: when n is odd, median is
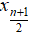 , when n is even, median is
, when n is even, median is 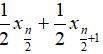
- Median absolute deviation:
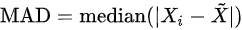 , where
, where 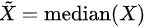
- Min:
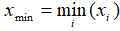
- Number of cells: Available when Calculate for is set to Features. Reports the number of cells with the value [<, <=, =, !=, > >=] (select one from the drop down list) than the cut off value entered in the text box. The cut off will be applied to the values present in the input data node, i.e. if invoked on non-normalised data node, the values are raw counts. For instance, use this option if you want to know the number of cells in which each feature was detected; possible filter: Number of cells whose value > 0.0
- Percent of cells: Available when Calculate for is set to Features. Reports the number of cells with the value [<, <=, =, !=, > >=] (select one from the drop down list) than the cut off value entered in the text box.
- Number of features: Available when Calculate for is set to Cells. Reports the number of features with the value [<, <=, =, !=, > >=] (select one from the drop down list) than the cut off value entered in the text box. The cut off will be applied to the values present in the input data node, i.e. if invoked on non-normalised data node, the values are raw counts. For example, use this option if you want to know the number of detected genes per each cell; filter: Number of features whose value > 0.0
- Percent of features: Available when Calculate for is set to Cells. Reports the fraction of features with the value [<, <=, =, !=, > >=] (select one from the drop down list) than the cut off value entered in the text box.
- Q1: 25th percentile
- Q3: 75th percentile
- Range: xmax - x min
- Standard deviation:
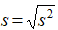 where
where 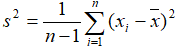
- Sum:
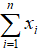
- Variance:
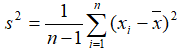
Left click to select measurement and drag to move to the right panel one at a time, or when you mouse over on a measurement, click on the green plus button to move to the right panel. When Sample (Cell) is select, the calculation will be performed on all the features in the input matrix for each sample (or cell). When Feature is selected, the calculation will be performed across all the samples (cells) in the input matrix for each feature.
In addition, when Feature is selected, there is an extra Group by option (Figure 3)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Click Finish to run
...
| |
|
From the drop-down list, choose a categorical attribute to calculate the descriptive statistics on all the subgroups for each feature.
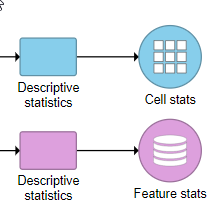
The output of the task is a matrix: Cell stats (result of Calculate for Cells) or Feature stats (result of Calculate for Features) (Figure 4). The results can be visualized in the Data Viewer.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

The intersection of observations (cells and/or samples) from the two input matrices is included in the merged matrix.
Once two data types have been merged, they can be split using Split matrix.
For a practical example using Merge matrices, please see our tutorial on Analyzing CITE-Seq Data,
| |||
|
| Additional assistance |
|---|
| Rate Macro | ||
|---|---|---|
|
...
Overview
Content Tools