Page History
| Children Display |
|---|
| Table of Contents |
|---|
This tutorial presents an outline of the basic series of steps for analyzing a 10x Genomics Gene Expression with Feature Barcoding (antibody) data set in Partek Flow starting with the output of Cell Ranger.
If you are starting with the raw data (FASTQ files), please begin with our Processing CITE-Seq data tutorial, which will take you from raw data to count matrix files. If you have Cell Hashing data, please see our documentation on Hashtag demultiplexing.
...
The data set for this tutorial is a demonstration data set from 10x Genomics. The sample includes cells from a dissociated Extranodal Marginal Zone B-Cell Tumor (MALT: Mucosa-Associated Lymphoid Tissue) stained with BioLegend TotalSeq-B antibodies. We are starting with the Feature / cell matrix HDF5 (filtered) produced by Cell Ranger.
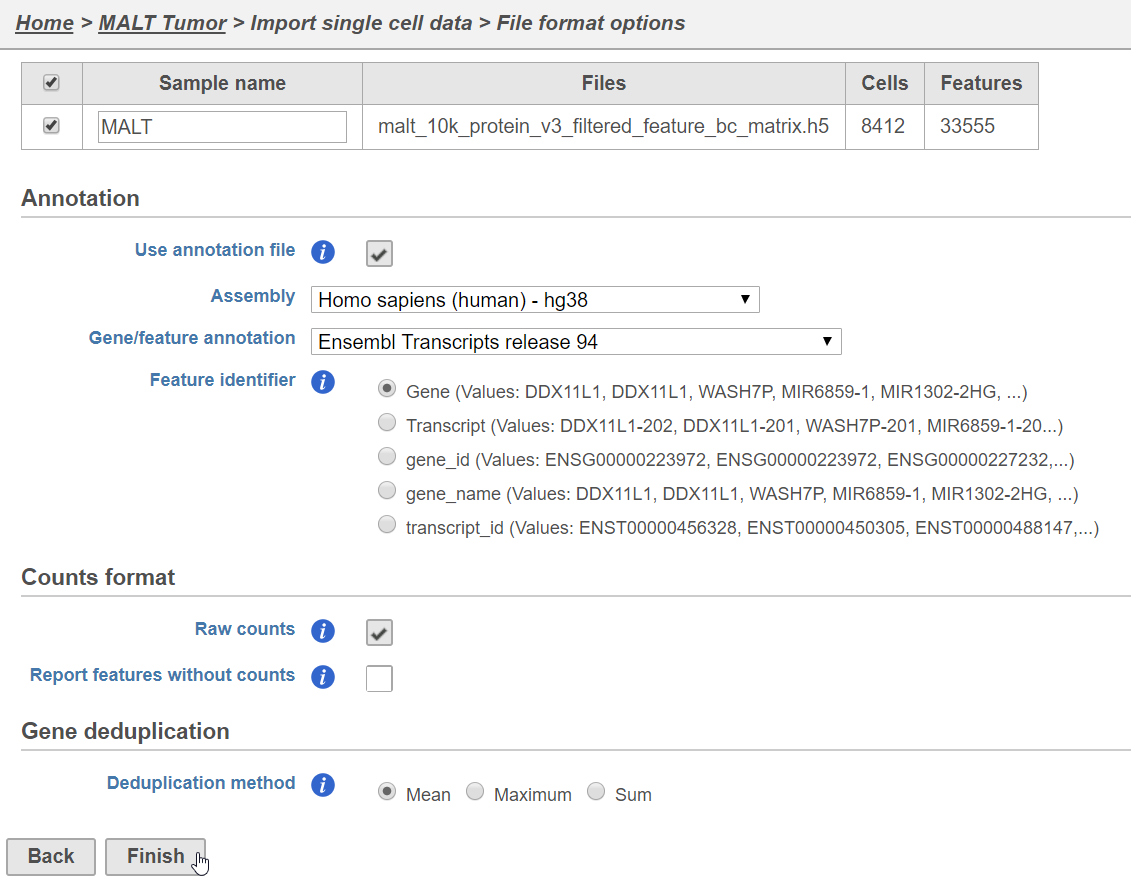
Importing feature barcoding data
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
A Single cell counts data node will be created after the file has been imported.
Split matrix
The Single cell counts data node contains two different types of data, mRNA measurements and protein measurements. So that we can process these two different types of data separately, we will split the data by data type.
- Click the Single cell counts data node
- Click the Pre-analysis tools section of the toolbox
- Click Split matrix
A rectangle, or task node, will be created for Split matrix along with two output circles, or data nodes, one for each data type (Figure 2). The labels for these data types are determined by features.csv file used when processing the data with Cell Ranger. Here, our data is labeled Gene Expression, for the mRNA data, and Antibody Capture, for the protein data.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Filter low-quality cells
An important step in analyzing single cell RNA-Seq data is to filter out low-quality cells. A few examples of low-quality cells are doublets, cells damaged during cell isolation, or cells with too few reads to be analyzed. In a CITE-Seq experiment, protein aggregation in the antibody staining reagents can cause a cell to have a very high number of counts; these are low-quality cells are can be excluded. Additionally, if all cells in a data set are expected to show a baseline level of expression for one of the antibodies used, it may be appropriate to filter out cells with very low counts. You can do this in Partek Flow using the Single cell QA/QC task.
We will start with the protein data.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

This produces a Single-cell QA/QC task node (Figure 4).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Double-click the Single cell QA/QC task node to open the task report
The task report lists the number of counts per cell and the number of detected features per cell in two violin plots. For more information, please see our documentation for the Single cell QA/QC task. For this analysis, we will set a maximum counts threshold to exclude potential protein aggregates and, because we expect every cell to be bound by several antibodies, we will also set a minimum counts threshold.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Click Apply filter to run the Filter cells task
The output is a Filtered single cell counts data node (Figure 6).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Next, we can repeat this process for the Gene Expression data node.
- Click the Gene Expression data node
- Click the QA/QC section in the toolbox
- Click Single Cell QA/QC
- Choose the assembly and annotation used for the gene expression data (Figure 3) from the drop-down menus
- Click Finish
This produces a Single-cell QA/QC task node (Figure 7).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Double-click the Single cell QA/QC task node to open the task report
The task report lists the number of counts per cell, the number of detected features per cell, and the percentage of mitochondrial reads per cell in three violin plots. For this analysis, we will set a maximum counts threshold maximum and minimum thresholds for total counts and detected genes to exclude potential doublets and a maximum mitochondrial reads percentage filter to exclude potential dead or dying cells.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Click Apply filter to run the Filter cells task
The output is a Filtered single cell counts data node (Figure 9).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Normalization
After excluding low-quality cells, we can normalize the data.
We will start with the protein data. We will normalize this data using Centered log-ratio (CLR). CLR was used to normalize antibody capture protein counts data in the paper that introudced CITE-Seq (Stoeckius et al. 2017) and in subsequent publications on similar assays (Stoeckiius et al. 2018, Mimitou et al. 2018). CLR normalization includes the following steps: Add 1, Divide by Geometric mean, Add 1, log base e.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Normalization produces a Normalized counts data node on the Antibody Capture branch of the pipeline.
Next, we can normalize the mRNA data. We will use the recommended normalization method in Partek Flow, which accounts for differences in library size, or the total number of UMI counts, per cell and log transforms the data. To match the CLR normalization used on the Antibody Capture data, we will use a log e transformation instead of the default log 2.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Normalization produces a Normalized counts data node on the Gene Expression branch of the pipeline (Figure 12).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Merge Protein and mRNA data
For quality filtering and normalization, we needed to have the two data types separate as the processing steps were distinct, but for downstream analysis we want to be able to analyze protein and mRNA data together. To bring the two data types back together, we will merge the two normalized counts data nodes.
- Click the Normalized counts data node on the Antibody Capture branch of the pipeline
- Click the Single cell counts data node
- Click the Pre-analysis tools section of the toolbox
- Click Merge matrices
- Click Select data node to launch the data node selector
Data nodes that can be merged with the Antibody Capture branch Normalized counts data node are shown in color (Figure 13).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Click the Normalized counts data node on the Gene Expression branch of the pipeline
A black outline will appear around the chosen data node.
- Click Select
- Click Finish to run the task
The output is a Merged counts data node (Figure 14). This data node will include the normalized counts of our protein and mRNA data. The intersection of cells from the two input data nodes is retained so only cells that passed the quality filter for both protein and mRNA data will be included in the Merged counts data node.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Collapsing tasks to simplify the pipeline
To simplify the appearance of the pipeline, we can group task nodes into a single collapsed task. Here, we will collapse the filtering and normalization steps.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Tasks that can for the beginning and end of the collapsed section of the pipeline are highlighted in purple (Figure 16). We have chosen the Split matrix task as the start and we can choose Merge matrices as the end of the collapsed section.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Click Merge matrices to choose it as the end of the collapsed section
The section of the pipeline that will form the collapsed task is highlighted in green.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

To view the tasks in Data processing, we can expand the collapsed task.
- Double-click Data processing to expand it
When expanded, the collapsed task is shown as a shaded section of the pipeline with a title bar (Figure 19).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

To re-collapse the task, you can double click the title bar or click the ![]() icon in the title bar. To remove the collapsed task, you can click the
icon in the title bar. To remove the collapsed task, you can click the ![]() . Please note that this will not remove tasks, just the grouping.
. Please note that this will not remove tasks, just the grouping.
- Double-click the Data processing title bar to re-collapse (Figure 18)
Choosing the number of PCs
In this data set, we have two data types. We can choose to run analysis tasks on one or both of the data types. Here, we will run PCA on only the mRNA data to find the optimal number of PCs for the mRNA data.
- Click the Merged counts node
- Click Exploratory analysis in the task menu
- Click PCA
Because we have multiple data types, we can choose which we want to use for the PCA calculation.
- Click Gene Expression for Include features where "Feature type" is
- Click Configure to access the advanced settings
- Click Generate PC quality measures
This will generate a Scree plot, which is useful for determining how many PCs to use in downstream analysis tasks.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

A PCA task node will be produced.
- Double-click the PCA task node to open the PCA task report
The PCA task report includes the PCA plot, the Scree plot, the component loadings table, and the PC projections table. To switch between these elements, use the buttons in the upper right-hand corner of the task report  . Each cell is shown as a dot on the PCA scatter plot.
. Each cell is shown as a dot on the PCA scatter plot.
- Click
 to open the Scree plot
to open the Scree plot
The Scree plot lists PCs on the x-axis and the amount of variance explained by each PC on the y-axis, measured in Eigenvalue. The higher the Eigenvalue, the more variance is explained by the PC. Typically, after an initial set of highly informative PCs, the amount of variance explained by analyzing additional PCs is minimal. By identifying the point where the Scree plot levels off, you can choose an optimal number of PCs to use in downstream analysis steps like graph-based clustering and t-SNE.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

In this data set, a reasonable cut-off could be set anywhere between around 10 and 30 PCs. We will use 15 in downstream steps.
Cluster by Gene Expression data
CITE-Seq data includes both gene and protein expression information. When the data types are combined, we can perform downstream analysis using both data types. We will begin with the mRNA data.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Once Graph-based clustering has finished running and produced a Clustering result data node, we can visualize the results using UMAP or t-SNE. Both are dimensional reduction techniques that group cells with similar expression into visible clusters.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

The Analyses tab now includes a UMAP task node (Figure 18).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Double-click the UMAP task node to open the task report
The UMAP task report includes a scatter plot with the clustering results coloring the points (Figure 19).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

An advantage of UMAP over t-SNE is that is preserves more of the global structure of the data. This means that with UMAP, more similar clusters are closer together while dissimilar clusters are further apart. With t-SNE, the relative positions of clusters to each other are often uninformative.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Classify from expression and clustering
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Because we merged the gene and protein expression data, we can visualize a mix of genes and proteins on the gene expression UMAP.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

This will color the plot by NKG7 gene expression and CD4 protein expression, a marker for helper T cells. We can add a third feature.
- Click
 to color by a second feature (gene or protein)
to color by a second feature (gene or protein) - Type CD3 and choose CD3_TotalSeqB from the drop-down
This will color the plot by NKG7 gene expression, CD4 protein expression, and CD3 protein expression. Each feature gets a color channel, green, red, or blue. Cells without expression are black and the mix of green, red, and blue is determined by the relative expression of the three genes. Cells expressing both CD4 protein (red) and CD3 protein (blue), but not NKG7 (green) are purple, while cells expressing both NKG7 (green) and CD3 protein (blue) are teal (Figure 25). CD3 is a pan-T cells marker, which helps confirm that this group of clusters is composed of T cells.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

In addition to coloring by the expression of genes and proteins, we can select cells by their expression levels.
- Click the Features tab in the Selection / Filtering section of the control panel
- Type NKG7 in the ID search bar of the Features tab
- Click NKG7 to select it
- Click to add a filter for NKG7 expression
By default, any cell that expresses >= 1 normalized count of NKG7 is now selected (Figure 26).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Type CD3 in the ID search bar of the Features tab
- Click CD3_TotalSeqB in the drop-down
- Click to add a filter for CD3 protein expression
Now, any cell that expresses >= 1 normalized count for NKG7 gene and CD3 protein is selected. You can also require that a cell not express a gene or protein.
- Type CD4 in the ID search bar of the Features tab
- Click CD4_TotalSeqB in the drop-down
- Click to add a filter for CD4 protein expression
- Set the CD4_TotalSeqB filter to <= 2
We have now selected only cells that express >= 1 normalized count for NKG7 gene and CD3 protein, but also have <= 2 normalized count for CD4 protein (Figure 27).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

We can classify these cells. Because they express the pan T cell maker, CD3, and the cytotoxic marker, NKG7, but not the helper T cell marker, CD4, we can classify these cells as Cytotoxic T cells.
- Click Classify selection
- Type Cytotoxic T cells for the name
- Click Save
To classify the helper T-cells, we can modify the selection criteria.
- Set NKG7 to =< 1
- Set CD4_TotalSeqB to >= 2
We have now selected the CD4 positive, CD3 positive, NKG7 negative helper T cells (Figure 28).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Click Classify selection
- Type Helper T cells for the name
- Click Save
We can check the results of our classification.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

To return to the full data set, we can clear the filter.
- Click Clear filters
The zoom level will also be reset (Figure 30).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

In addition to T-cells, we would expect to see B lymphocytes, at least some of which are malignant, in a MALT tumor sample. We can color the plot by expression of a B cell marker to locate these cells on the UMAP plot.
- Choose Expression from the Color by drop-down menu
- Type CD19 in the search box
- Click CD19_TotalSeqB in the drop-down
There are several clusters that show high levels of CD19 protein expression (Figure 31). We can filter to these cells to examine them more closely.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

We can use information from the graph-based clustering results to help us find sub-groups within the CD19 protein-expressing cells.
- Choose Graph-based from the Color by drop-down menu
With the help of the Group biomarkers table, we can quickly characterize a few notable sub-groups based on their clusters (Figure 33).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Cluster 7, shown in pink, lists IL7R and CD3D, genes typically expressed by T cells, as two of its top biomarkers. Biomarkers are genes or proteins that are expressed highly in a clusters when compared with the other clusters. Therefore, the cells in cluster 7 are likely doublets as they express both B cell (CD19) and T cell (CD3D) markers.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Click the check box for 7 to select cluster 7
- Click Classify selection
- Name the cells Doublets
- Click Save
- Click Clear selection
The biomarkers for clusters 1 and 2 also show an interesting pattern. Cluster 1 lists IGHD as its top biomarker, while cluster 2 lists IGHA1. Both IGHD (Immunoglobulin Heavy Constant Delta) and IGHA1 (Immunoglobulin Heavy Constant Alpha 1) encode classes of the immunoglobulin heavy chain constant region. IGHD is part of IgD, which is expressed by mature B cells, and IGHA1 is part of IgA1, which is produced by plasma cells. We can color the plot by both of these genes to visualize their expression.
- Click IGHD in the Group biomarkers table
- Hold Ctrl on your keyboard and click IGHA1 in the Group biomarkers table
This will color the plot by IGHD and IGHA1 (Figure 35).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

The clusters on the left show expression of IGHA1 while the larger or the two clusters on the right expresses IGHD. We can use the lasso tool to classify these populations.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Click Classify selection
- Name them Plasma cells
- Click Save
- Double-click any white-space on the plot to clear the selection
We can now classify the cluster that expresses IGHD as mature B cells.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Click Classify selection
- Name them Mature B cells
- Click Save
- Double-click any white-space on the plot to clear the selection
We can visualize our classifications.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

To use these classifications in downstream, we can apply the classifications.
- Click Apply classifications
- Click Apply to confirm
This will produce a Classified groups data node.
Clustering by protein expression
In addition to performing clustering by gene expression data, we can use the protein data for clustering and UMAP visualization.
- Click the Classified groups data node
- Click Exploratory analysis in the toolbox
- Click Graph-based clustering
- Click Antibody Capture for Include features where "Feature type" is
- Click Finish to run
Notice that we did not set the number of PCs in this case. If there are fewer than 50 proteins in the data set, all possible PCs will be used by default and, because using all the PCs will capture all of the variance in the data set, this is equivalent to running clustering on the original data. If you data set has more than 50 proteins and you want to run clustering on full data instead of a subset of PCs, simply set the number of PCs to All in the advanced settings.
- Click the Clustering result data node
- Click Exploratory analysis in the toolbox
- Click UMAP
- Click Antibody Capture for Include features where "Feature type" is
- Click Finish to run
We can open the UMAP task report to view the clustering result.
- Double-click the UMAP task node
- Click Group biomarkers to minimize the biomarkers table
UMAP using the protein expression data resolves the cell types we identified earlier on the gene expression UMAP (Figure 39).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

We can take a closer look at the helper T cell cluster to see if any additional cell types can be found using the protein expression data.
- Click
 to activate the lasso tool
to activate the lasso tool - Draw a lasso around the Helper T cell cluster to select them
- Click
 to filter to include only the selected cells
to filter to include only the selected cells - Click
 to rescale the axes to the included cells
to rescale the axes to the included cells
With that, let's take a look at the clustering results from the protein expression data for these cells.
- Choose Graph-based from the Color by drop-down menu
Please note that Graph-based always refers to the most recent graph-based clustering result in the pipeline.
- Click Group biomarkers to expand the biomarkers table
- Select Graph-based from the Method drop-down menu (Figure 40)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

The far-left cluster, cluster 8, has several interesting biomarkers. The top biomarker, is CXCL13, a gene expressed by follicular B helper T cells (Tfh cells). Two of the other biomarkers are PD-1 protein, which promotes self-tolerance and is a target for immunotherapy drugs, and TIGIT, another immunotherapy drug target.
- Choose Expression from the Color by drop-down menu
- Type PD-1 in the search box and choose PD-1_TotalSeqB from the drop-down
PD-1 expression is highest in cluster 8 with uniformly strong expression throughout (Figure 41).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Type PDCD1 in the Expression search box and choose PDCD1 from the drop-down
It is interesting to note that this pattern of PD-1 expression is not easily discernible at the PD-1 gene expression level (PDCD1) (Figure 42).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Type CXCL13 in the Expression search box and choose CXCL13 from the drop-down
The Tfh cell marker, CXCL13, is highly and specifically expressed in cluster 8, so we will classify these cells as Tfh (Figure 43).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Choose Graph-based from the Select by drop-down in the Attributes tab of the Selection / Filtering section of the control panel
- Click the check box for 8 to select cluster 8
- Click Classify selection
- Name the cells Tfh cells
- Click Save
- Choose Classifications from the Color by drop-down menu
- Click Clear selection
- Click Clear filters to return to the full data set
- Click Apply classifications
Prior to beginning, transfer this file to your Partek Flow using the Transfer files button on the homepage.
| Page Turner | ||
|---|---|---|
|
| Additional assistance |
|---|
| Rate Macro |
|---|
Overview
Content Tools