Page History
...
K-means clustering is a method for identifying groups of similar observations, i.e. cells or samples. K-means clustering aims to group observations into a pre-determined number of clusters (k) so that each observation belongs to the cluster with the nearest mean. An important aspect of K-means clustering is that it expects clusters to be of similar size (equal variance) and shape (distribution of variance is spherical). The Compare Clusters task can also be used to help determine the optimal number of K-means clusters.
Running K-means clustering
...
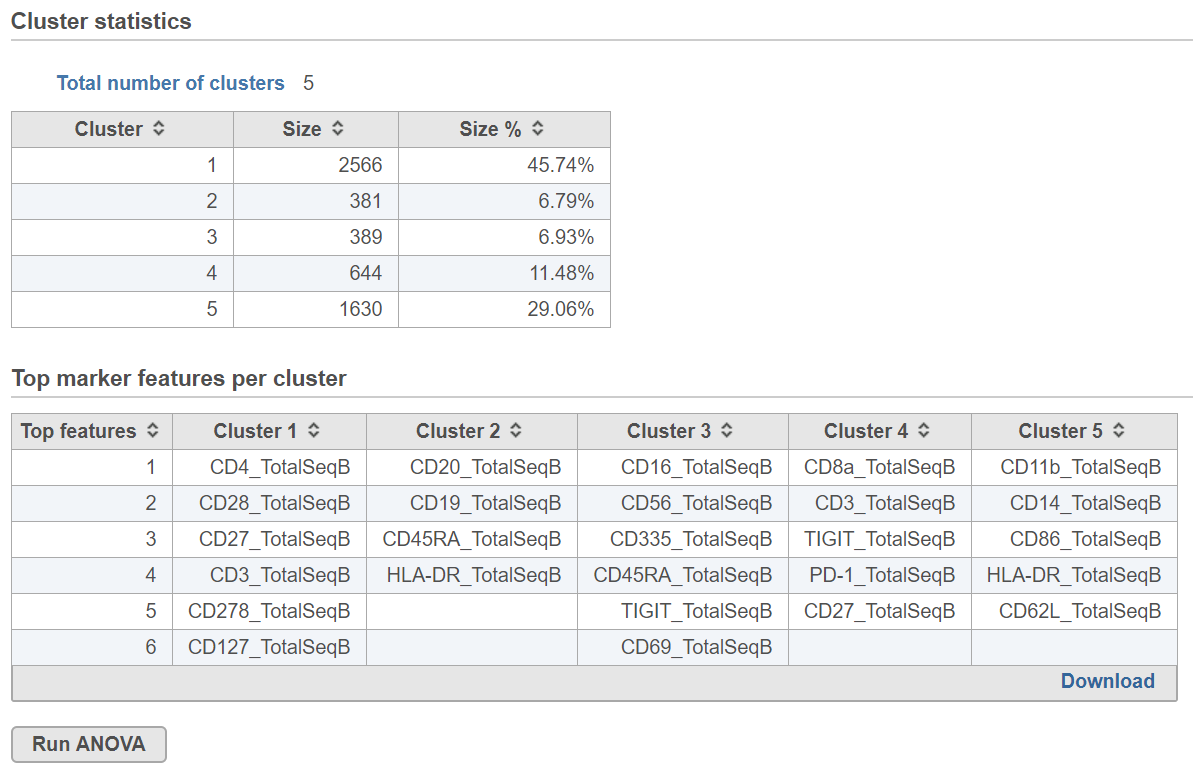
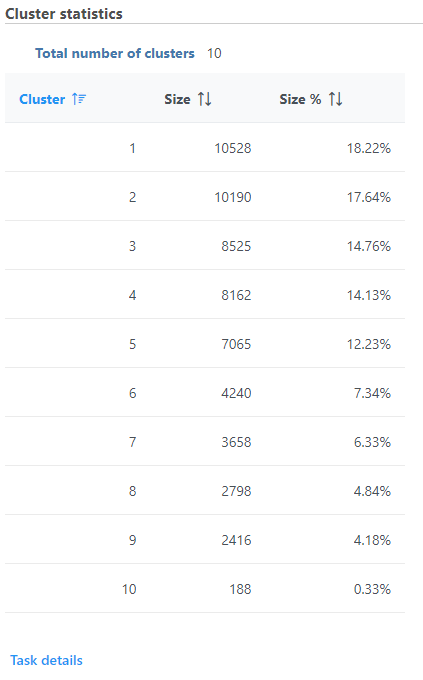
K-means clustering produces a K-means Clusters result data node; double-click to open the task report which lists the cluster statistics (Figure 2). If Compute biomarkers was enabled, top markers will be available by double-clicking the Biomarkers result data node. If clustering was run with Split cells by sample enabled on a single cell counts data node, the cluster results table displays the number of clusters found for each sample and clicking the sample name opens the sample-level report.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
Cluster statistics
The total number of clusters is listed along with the number and percentage of cells in each cluster.
Top marker features per cluster
Biomarkers for each cluster are calculated using an ANVOA test where each cluster is compared to the other cells in the data set, genes with fold-change > 1.5 are included, and these genes are sorted by ascending p-value (ties broken by greater fold change). The top 10 genes for each cluster are shown in the table. The full gene list can be obtained as a text file by selecting the Download link. The full ANOVA results can be obtained by clicking the Run ANOVA button, which will generate a Feature list data node. Open the node to perform filtering based on p-value and/or fold-change or to invoke a volcano plot.
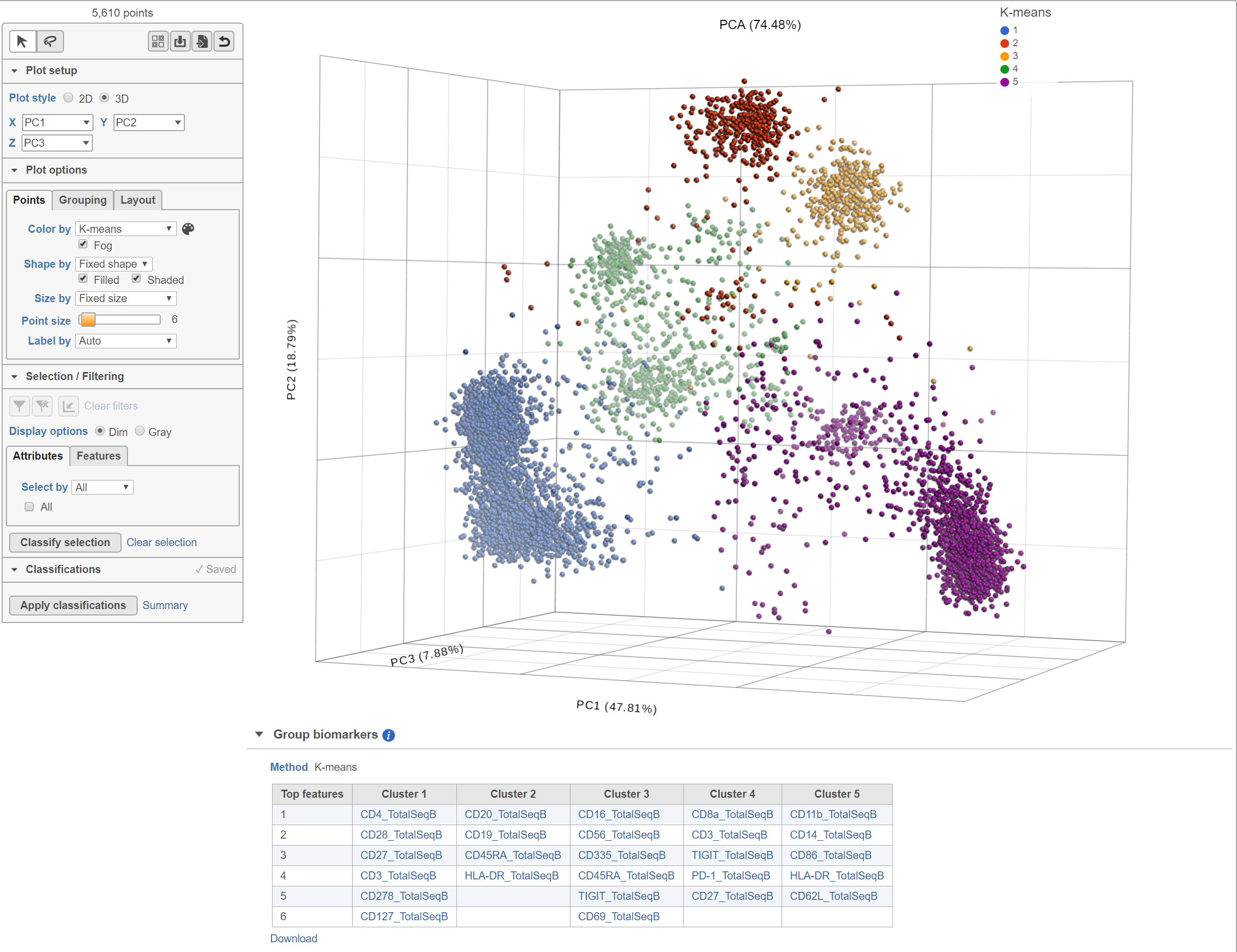
The Clustering result data The K-means Clustering result data node includes the input values for each gene and adds cluster assignment as a new attribute, K-means, for each observation. If the Clustering result K-means clusters data node is visualized by Scatter plot, PCA, t-SNE, or UMAP, the plot will can be colored by the K-means attribute and the group biomarker table, if generated, will be included below the plot (Figure 3).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
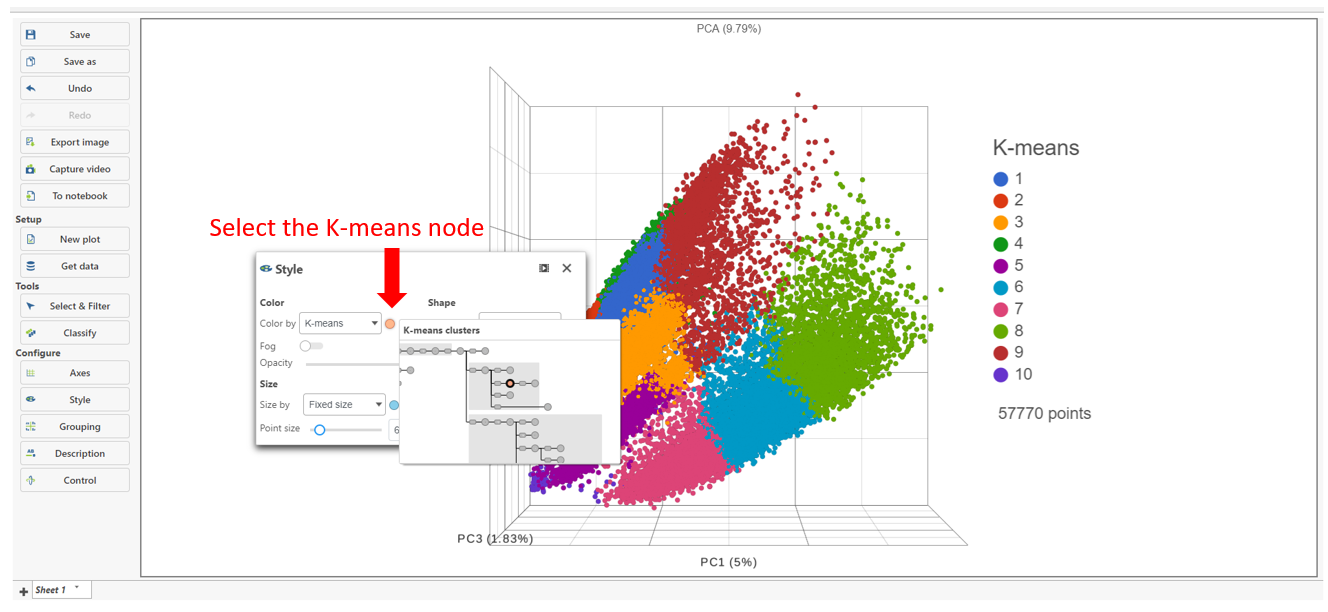
Basic K-means clustering parameters
...
Overview
Content Tools