Page History
...
In the annotation file, there might be multiple features in the same location, or one read might have multiple alignments, so the read count of a feature might not be an integer. Our white paper on the Partek E/M algorithm has more details on Partek’s implementation the E/M algorithm initially described by Xing et al. [21]
Quantify to annotation model (Partek E/M) output
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
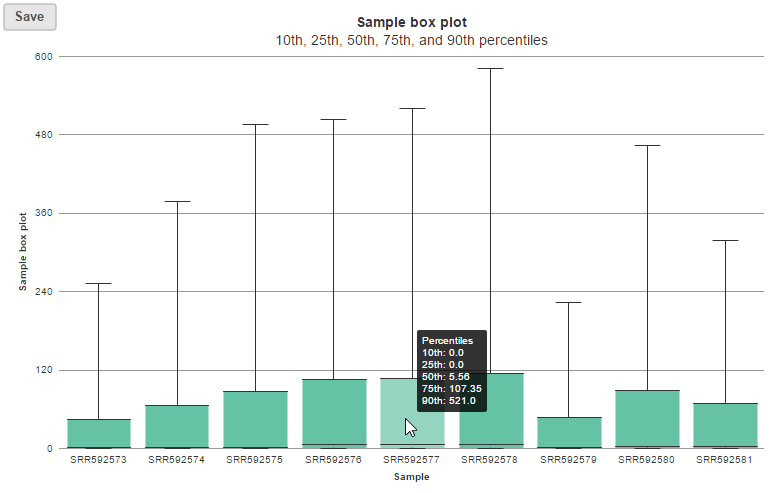
In sample histogram, each line represents a sample and the range of read counts are divided into 20 bins. Clicking on a sample in the legend will hide the line for that specific sample. Hovering over each circle displays detailed information about the sample and that specific bin (Figure 9). The information includes:
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
References
- Trapnell C, Williams B, Pertea G, et al. Transcript assembly and quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation. Nature Biotech. 2010; 28:511-515.
- Xing Y, Yu T, Wu YN, Roy M, Kim J, Lee C. An expectation-maximization algorithm for probabilistic reconstructions of full-length isoforms from splice graphs. Nucleic Acids Res. 2006; 34(10):3150-60.
...
Overview
Content Tools