Page History
Post-alignment QA/QC is available for data nodes containing aligned reads (Aligned reads) and has no special control dialog. Similar to the pre-alignment QA/QC report, the post-alignment contains two tiers, i.e. project-level report and sample-level report.
...
The first two columns contain total number of reads (Total reads) and total number of alignments (Total alignments). Theoretically, for single-end chemistry, total number of reds equals total number of alignments. For double-end reads, theoretical result is to have twice as many alignments as reads (the term “read” refers to the fragment being sequenced, and since each fragment is sequenced from two directions, one can expect to get two alignments per fragment). When counting the actual number of alignments (Total alignments), however, reads that align more than once (multimappers) are also taken into account. Next, the Aligned column contains the fraction of all the reads that were aligned to the reference assembly.
The Coverage column shows the fraction (%) of the reference assembly that was sequenced and the average sequencing coverage (×) of the covered regions is in the Avg. coverage depth column. The Avg. quality is mapping quality, as reported by the aligner (not all aligners support this metric). Avg. length is the average read length and average read quality is given in Avg. quality column. Finally, %GC is the fraction of G or C calls.
In addition, the Post-alignment QA/QC report for single-end reads (Figure 1) contains the Unique column. This refers to the fraction of uniquely aligned reads.
...
- Unique singleton
- fraction of alignments corresponding to the reads where only one of the paired reads can be uniquely aligned
- Unique paired
- fraction of alignments corresponding to the reads where both of the paired reads can be uniquely aligned
- Non-unique singleton
- fraction of singletons that align to multiple locations
- Non-unique paired
- fraction of paired reads that align to multiple locations
...
In addition to the summary table, several graphs are plotted to give a comparison across multiple samples in the project. Those graphs are Alignment breakdown, Coverage, Average base quality per position, Average base quality score per read, and Average alignments per read. Two of those (Average base quality plots) have already been described.
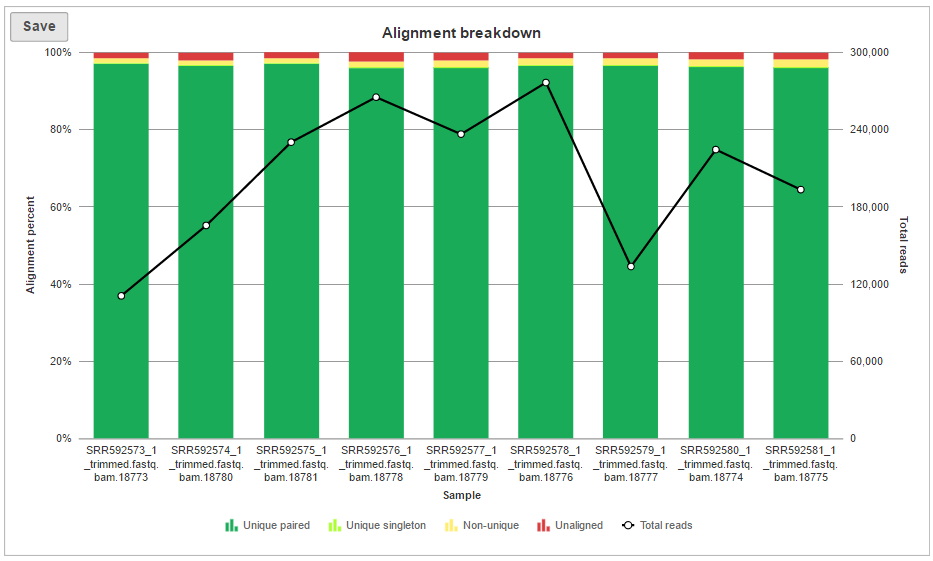
The alignment breakdown chart (Figure 3) presents each sample as a column, and has two vertical axes (i.e. Alignment percent and Total reads). The percentage of reads with different alignment outcomes (Unique paired, Unique singleton, Non-unique, Unaligned) is represented by the left-side y-axis and visualized by stacked columns. The total number of reads in each sample is given using the black line and shown on the right-side y-axis.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
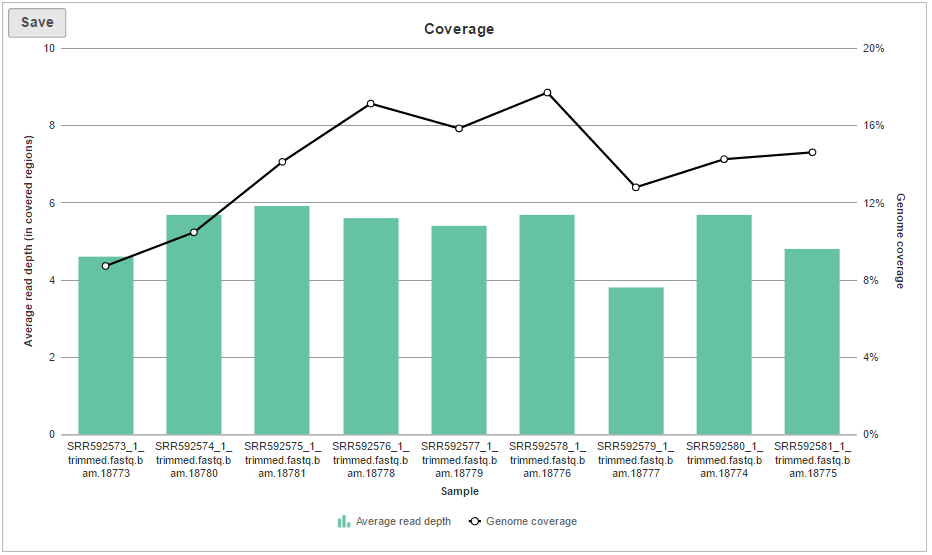
The Coverage plot (Figure 4) shows the Average read depth (in covered regions) for each sample using columns and can be red off the left-hand y-axis. On the same plot, the percentage of covered genome bases (Genome coverage) in each sample is represented by the black line and quantified by the right-hand y-axis.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
The last graph is Average alignments per read (Figure 5) and shows the average number of alignments for each read, with samples as columns. For single-end data, the expected average alignments per read is one, while for paired-end data, the expected average alignments per read is two.
...
Overview
Content Tools