Page History
This white paper explains some basic concepts related to alignment and mapping quantification tasks in Partek® Genomics Suite™ (PGS) v6.6 under the RNA-seq workflow. Flow®. The term “alignment” describes the process of finding the position of a sequencing read on the reference genome, while “mapping” quantification refers to assigning already aligned reads to transcripts ; it is also called quantificationbased on specified transcripts/gene annotation.
| Table of Contents | ||||||
|---|---|---|---|---|---|---|
|
Number of Reads and Alignments
PGS imports all the sequencing Aligned data node contains reads that have been aligned, counting each read once even if it has multiple alignments. Processing of paired-end reads needs further elaboration: a paired-end read will be counted as one read only if both ends align to the genome, no matter how many alignments each end has (Figure 1). If one end of a paired-end read is not aligned, the read will be discarded (i.e., not imported).considered unaligned and will be discarded for the downstream analysis.
As reads can be aligned to more than one location, the number of alignments may be greater than the number of reads; since some reads may be unaligned, the number of alignments may be less than the number of reads in the bam/sam file (Figure 1).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
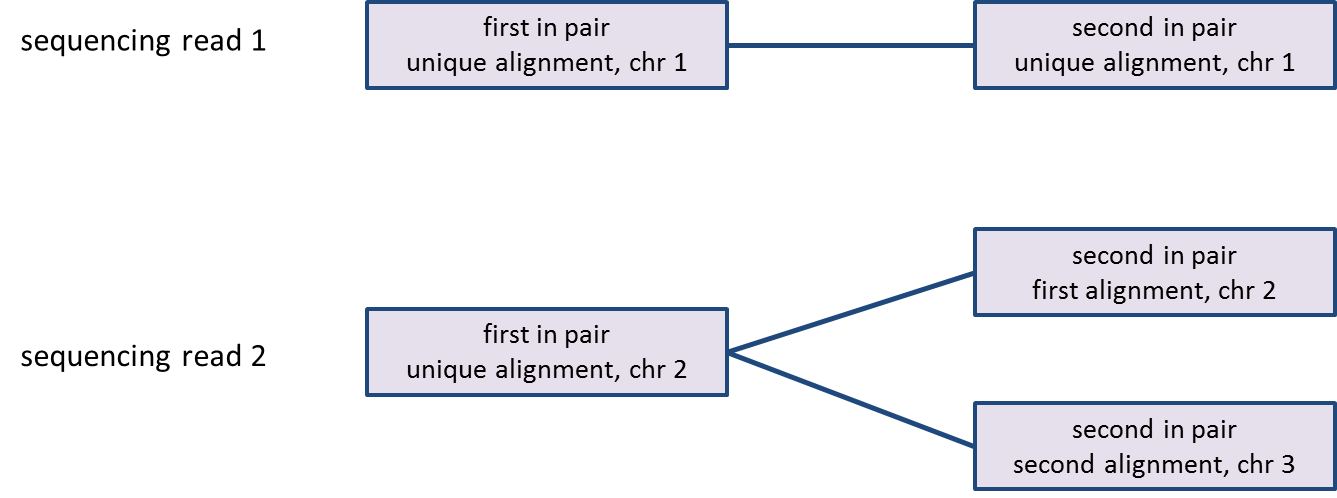
PGS Partek Flow shows the number of alignments per sample in the “parent” spreadsheet of a RNA-seq project, while the alignments and reads per sample are reported in the mapping_summary spreadsheet. The alignment_counts spreadsheet contains the number of alignments per read in each sample and it can be invoked through the QA/QC section of the RNA-seq workflowalignments as well as the aligned reads percentage per sample in the post alignment QC report.
Quantification: Assigning Reads to Transcripts
...
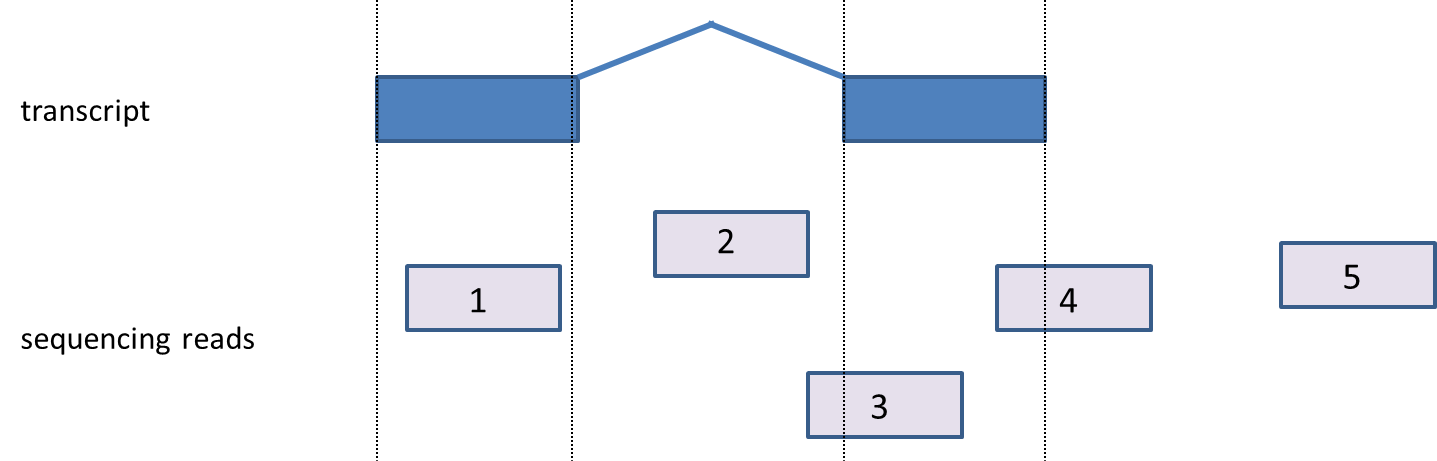
- Exonic: A read is labeled exonic if any one of its alignments is completely contained within the respective exon as defined by the database (read 1) ,i.e., even if there is a single base shift of the read relative to the exon, the read will not be called exonic but will fall in the category ‘partially overlaps exon’). If the alignments are strandspecificstrand specific, then the strand of the alignment must also agree with the strand of the transcript.
- Partially overlaps exon: A read is assigned to partially overlap an exon if any of its alignments overlaps an exon, but at least partly (one base-pair or more) maps out of the exon (read 3, read 4).
- Intronic: A read is labeled intronic if any one of its alignments maps completely within an intron (read 2), but none of the alignments are exonic (either fully or in part). If the alignments are strand-specific, then the strand of the alignment must also agree with the strand of the transcript.
- Reads between genes: A read is labeled ‘between genes’ if none of its alignments overlap a gene (read 5).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
...
Reads that are partially mapped exon reads, intronic reads, intergenic reads are incompatible with any transcript. Incompatible reads do not contribute to gene or transcript level read counts. Several single-end and paired-end scenarios will be discussed in the following sections.
In addition, the implementation of the compatibility rules has been changed between PGS releases 6.5 and 6.6 thus leading to possible differences in the read counts between the two versions. The major difference is that 6.6 is more strict: 6.5 would count a paired-end read as compatible if it had any alignments that are compatible as opposed to 6.6 which requires both first-in-pair and second-in-pair to be compatible.
Single-End Scenarios
A single-end read that is considered “compatible” would be any read that overlaps the exon 100% as described above in the paragraph on “exonic” reads.
...
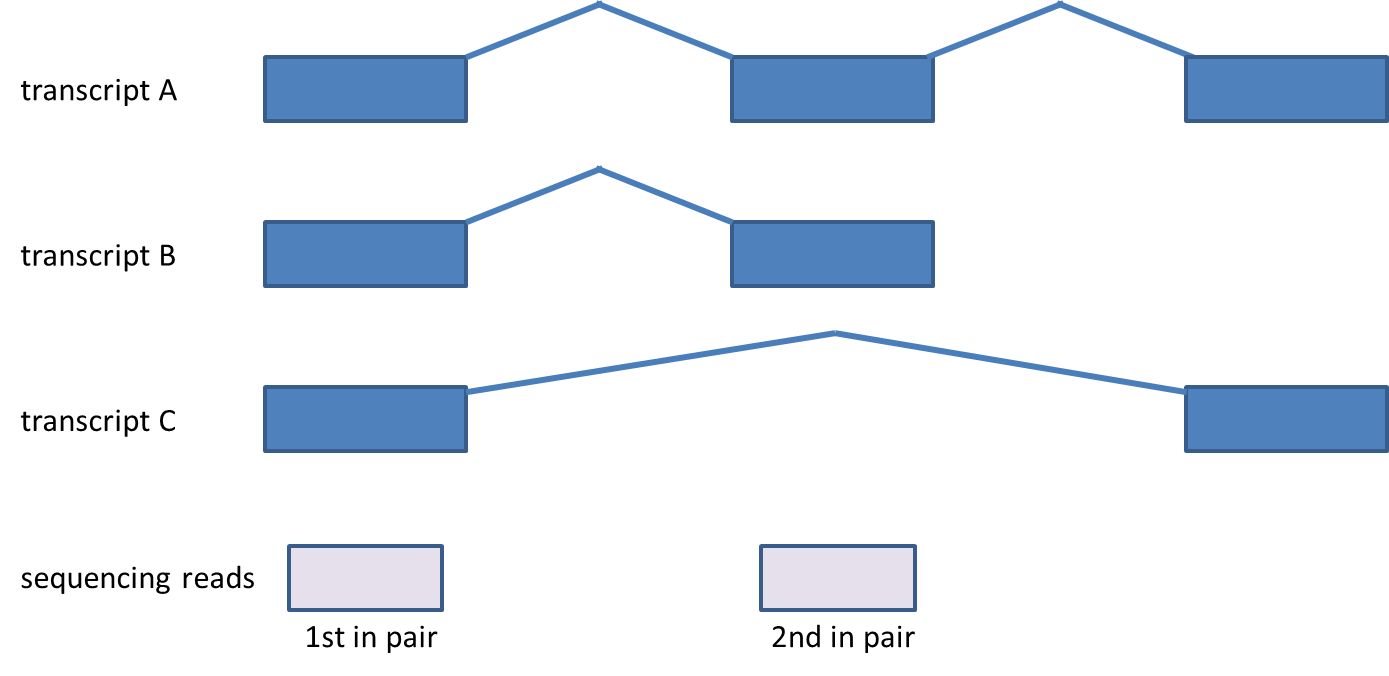
Considering genes with multiple transcripts, a read can be both counted as compatible for some transcripts, as well as counted incompatible for other transcripts of the same gene (Figure 3). Please note that this concept holds for single-end reads as well.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
Furthermore, all the reads that have at least one alignment contribute to the total number of aligned reads.
With respect to the gene-level summarization, user can decide whether or not to consider intronic reads (both single- and paired-end) as compatible with the gene (Figure 4). In the latter case, the entire gene is basically treated as one giant exon. In the case that one end of a paired-end read falls within a gene, and the other end does not, the read will not be included in the gene-level summarization.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Unexplained regions
The unexplained regions portion of quantification considers any read that is considered “not compatible” with all transcripts. It is basically a 3 step process:
...
When interpreting the unexplained reads, you should have in mind that these are actually the reads not compatible with the applied transcript model. By changing the model, some reads will become compatible and thus will not be labeled “unexplained” any more. Figure 6 shows such an example. The depicted regions map just downstream of the human LONP2 gene as defined by RefSeq and are hence flagged as unexplained. However, by overlaying the AceView transcripts, it is apparent that mapping to AceView would yield a different result.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

| Additional assistance |
|---|
| Rate Macro | ||
|---|---|---|
|
...
Overview
Content Tools