The Split by Attribute task is used to split a data node into different nodes based on the groups in a categorical attribute, each data node only includes the samples/cells from one group. It is a more efficient way to filter your data if you plan to perform downstream analysis on each and every group separately in an attribute.
Click on the data node and select split by attribute from the Filtering section in task menu (Figure 1).
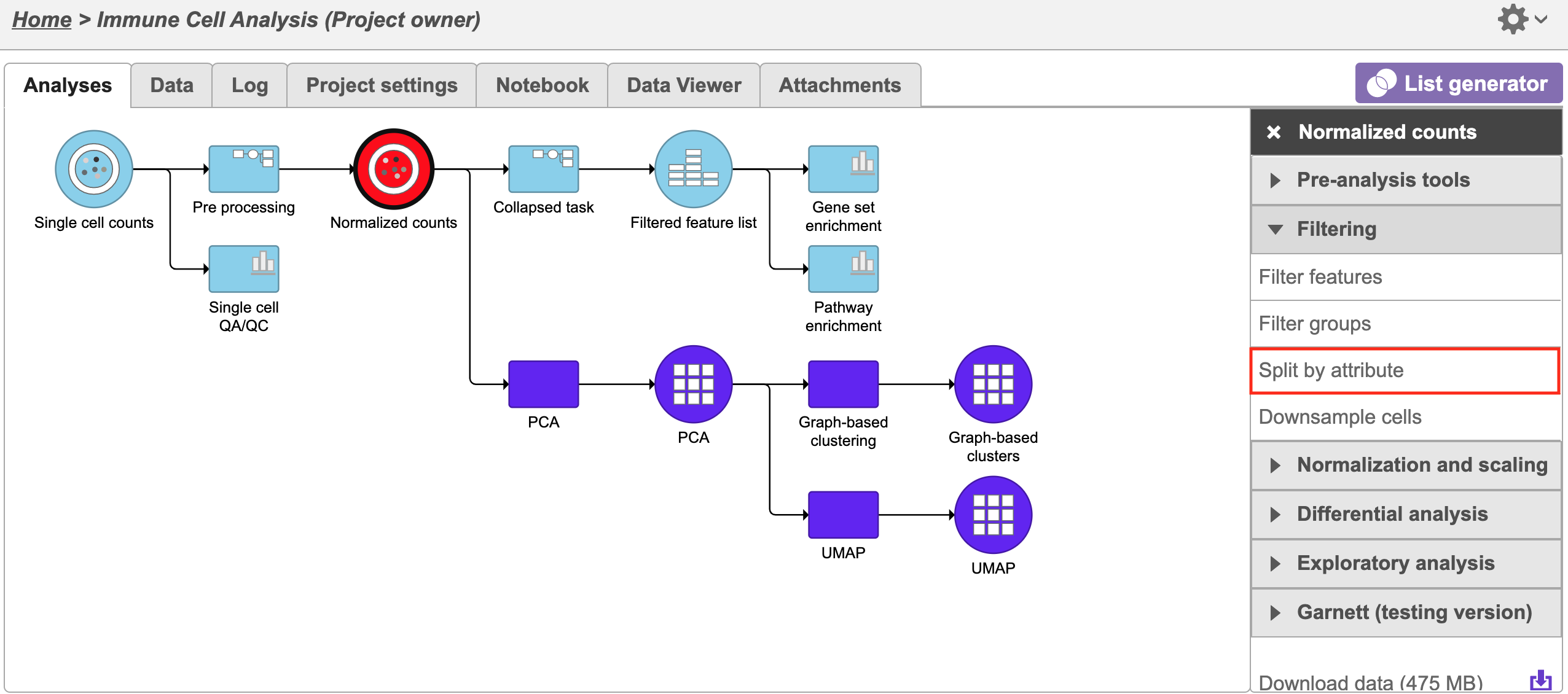 Figure 1. Single Click on Data node to be split (red) and select the split by attribute task (red rectangle) from the filtering menu
Select the attribute to split the data on. In this case, data will be split according to the Age attribute (Figure 2).
Figure 1. Single Click on Data node to be split (red) and select the split by attribute task (red rectangle) from the filtering menu
Select the attribute to split the data on. In this case, data will be split according to the Age attribute (Figure 2).
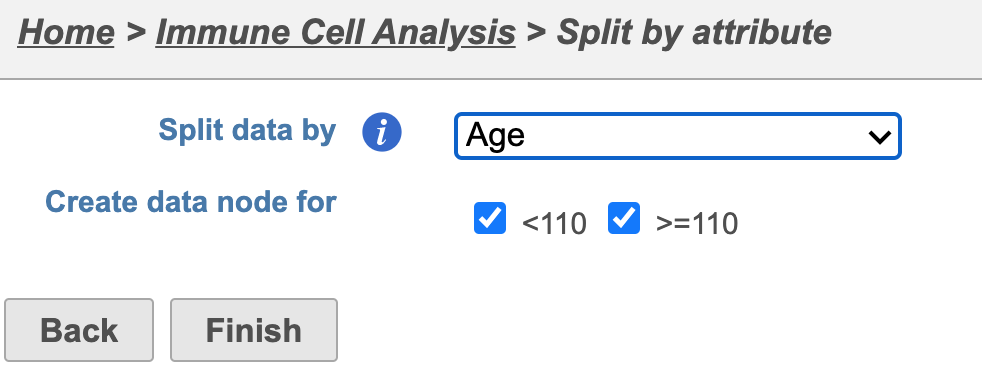 Figure 2. Splitting data into >110 and <110 groups of the Age category. Click Finish
Result of the split by attribute task will be two separate data nodes, each contains samples from one age group (Figure 3).
Figure 2. Splitting data into >110 and <110 groups of the Age category. Click Finish
Result of the split by attribute task will be two separate data nodes, each contains samples from one age group (Figure 3).
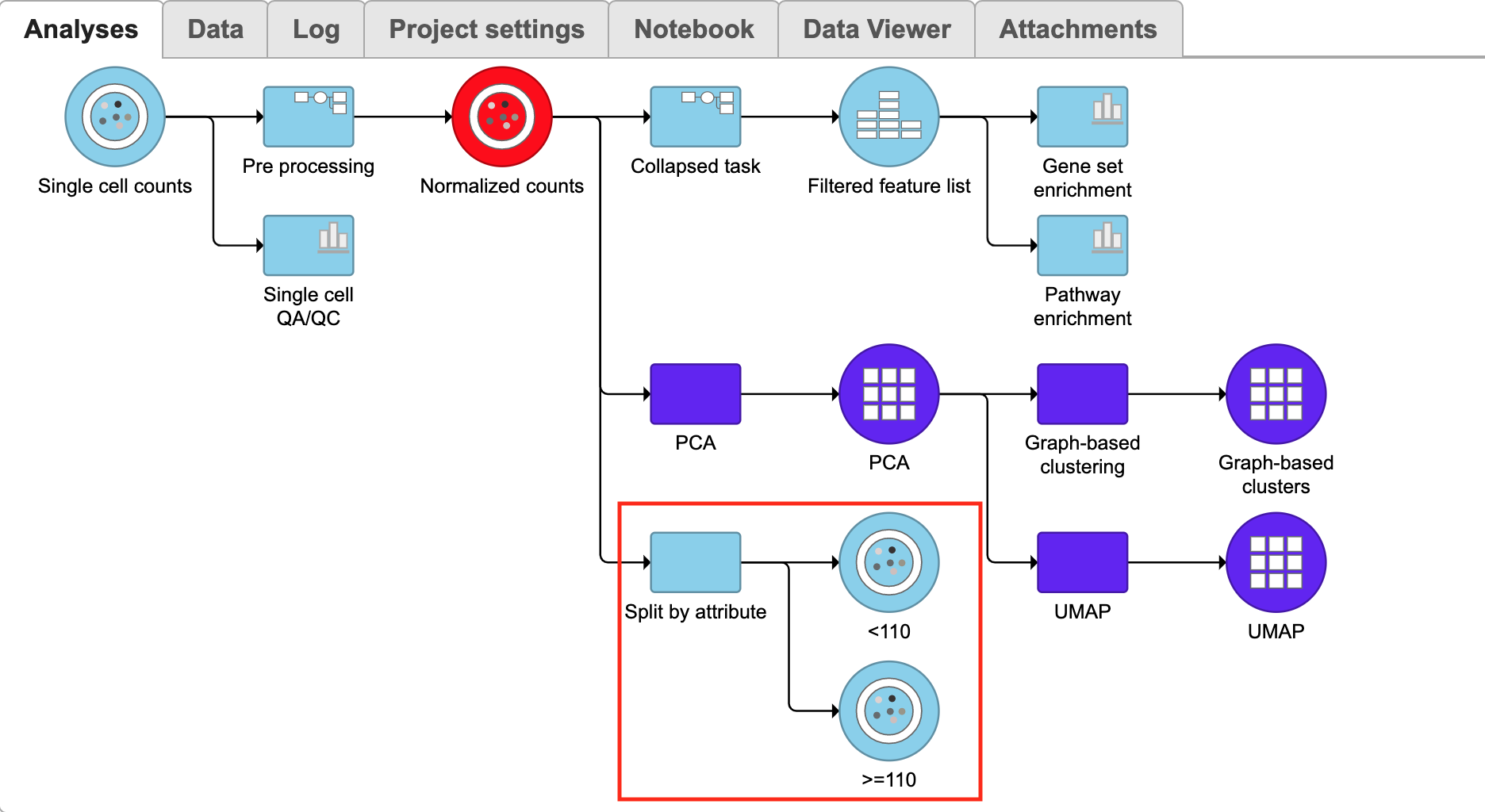
Figure 3. Count data node split into two :>110 and <110 data nodes (red rectangle)
To download a text-file version of one of the tables, click Download in lower right-hand corner of the table.
Additional Assistance
If you need additional assistance, please visit our support page to submit a help ticket or find phone numbers for regional support.


| Your Rating: |
|
Results: |

|
12 | rates |
Overview
Content Tools