The ERCC (External RNA Control Consortium) developed a set of RNA standards for quality control in microarray, qPCR, and sequencing applications. These RNA standards are spiked-in RNA with known concentrations and composition (i.e. sequence length and GC content). They can be used to evaluate sensitivity and accuracy of RNA-seq data.
The ERCC analysis is performed on unaligned data, if the ERCC RNA standards have been added to the samples. There are 92 ERCC spiked-in sequences with different concentrations and different compositions. The idea is that the raw data will be aligned (with Bowtie) to the known ERCC-RNA sequences to get the count of each ERCC sequence. This information is available within Partek Flow and will be used to plot the correlation between the observed counts and the expected concentration. If there is a high correlation between the observed counts versus the expected concentration, you can be confident that the quantified RNA-seq data are reliable. Partek Flow supports Mix1 and Mix 2 ERCC formulations. Both formulations use the same ERCC sequences, but each sequence is present at different expected concentrations. If both Mix 1 and Mix 2 formulations have been used, ExFold comparison can be performed to compare the observed and expected Mix1:Mix2 ratio for each spike-in.
To start ERCC assessment, select an unaligned reads node and choose ERCC in the context sensitive menu. If all samples in the project have used the Mix 1 or Mix 2 formulation, choose the appropriate radio button at the top (Figure 1).
Figure 1. Setting up advanced options for the alignment of ERCC controls using Bowtie
If some samples have been treated with the Mix 1 formulation and others have been treated with the Mix 2 formulation, choose the ExFold comparison radio button (Figure 2). Set up the pairwise comparisons by choosing the Mix 1 and Mix 2 samples that you wish to compare from the drop-down lists, followed by the green plus (![]() ) icon. The selected pair of samples will be added to the table below.
) icon. The selected pair of samples will be added to the table below.
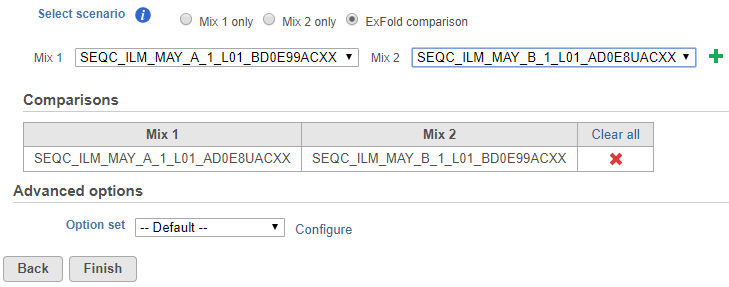 Figure 2. ExFold comparison can be performed between specified Mix 1 and Mix 2 pairs of samples
You can change the Bowtie parameters by clicking Configure before the alignment (Figure 1), although the default parameters work fine for most data. Once the task has been set up correctly, select Finish.
Figure 2. ExFold comparison can be performed between specified Mix 1 and Mix 2 pairs of samples
You can change the Bowtie parameters by clicking Configure before the alignment (Figure 1), although the default parameters work fine for most data. Once the task has been set up correctly, select Finish.
ERCC task report starts with a table (Figure 3), which summarizes the result on the project level. The table shows which samples use the Mix 1 or Mix 2 formulation. The total number of alignments to the ERCC controls are also shown, which is further divided into the total number of alignments to the forward strand and the reverse strand. The summary table also gives the percentage of ERCC controls that contain alignment counts (i.e. are present). Generally, the fraction of present controls should be as high as possible, however, there are certain ERCC controls that may not contain alignment counts due to their low concentration; that information is useful for evaluation of the sensitivity of the RNA-seq experiment. The coefficient of determination (R squared) of the present ERCC controls is listed in the next column. As a rule of a thumb, you should expect a good correlation between the observed alignment counts and the actual concentration, or else the RNA-seq quantification results may not be accurate. Finally, the last two columns give estimates of bias with regards to sequence length and GC content, by giving the correlation of the alignment counts with the sequence length and the GC content, respectively.

Figure 3. Summary of ERCC assessment. Each row is a sample (an example is shown)
If ExFold comparison was enabled, an extra table will be produced in the ERCC task report (Figure 4). Each row in the table is a pairwise comparison. This table lists the percentage of ERCC controls present in the Mix 1 and Mix 2 samples and the R squared for the observed vs expected Mix1:Mix2 ratios.
 Figure 4. Summary of ExFold comparison. Each row is a different pairwise comparison
The ERCC spike-ins plot (Figure 5) shows the regression lines between the actual spike-in concentration (x-axis, given in log2 space) and the observed alignment counts (y-axis, given in log2 space), for all the samples in the project. The samples are depicted as lines, and the probes with the highest and lowest concentration are highlighted as dots. The regression line for a particular sample can be turned off by simply clicking on the sample name in the legend beneath the plot.
Figure 4. Summary of ExFold comparison. Each row is a different pairwise comparison
The ERCC spike-ins plot (Figure 5) shows the regression lines between the actual spike-in concentration (x-axis, given in log2 space) and the observed alignment counts (y-axis, given in log2 space), for all the samples in the project. The samples are depicted as lines, and the probes with the highest and lowest concentration are highlighted as dots. The regression line for a particular sample can be turned off by simply clicking on the sample name in the legend beneath the plot.
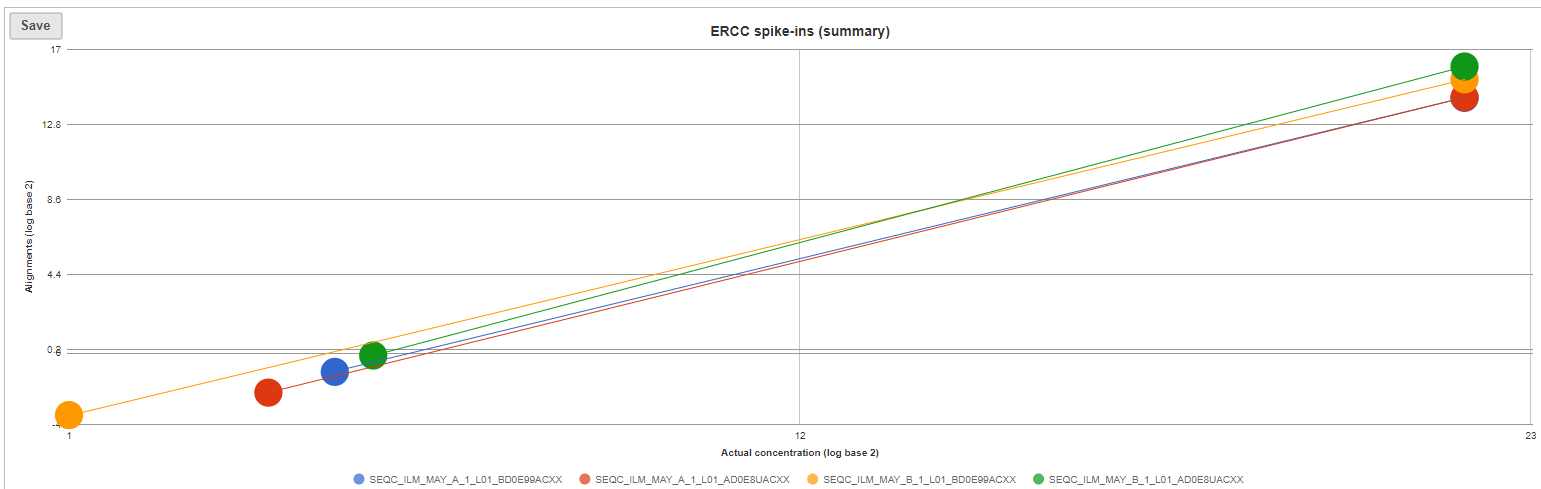
Figure 5. ERCC spike-ins plot. Lines (one per sample) correspond to regression lines between actual spike-in concentrations and observed number of alignments. Dots represent present ERCC sequences with the lowest and the highest concentration
Optionally, you can invoke a principal components analysis plot (View PCA), which is based on RPKM-normalised counts, using the ERCC sequences as the annotation file (not shown).
For more details, go to the sample-level report (Figure 6) by selecting a sample name on the summary table. First, you will get a comprehensive scatter plot of observed alignment counts (y-axis, in log2 space) vs. the actual spike-in concentration (x-axis, in log2 space). Each dot on the plot represents an ERCC sequence, coloured based on GC content and sized by sequence length (plot controls are on the right).
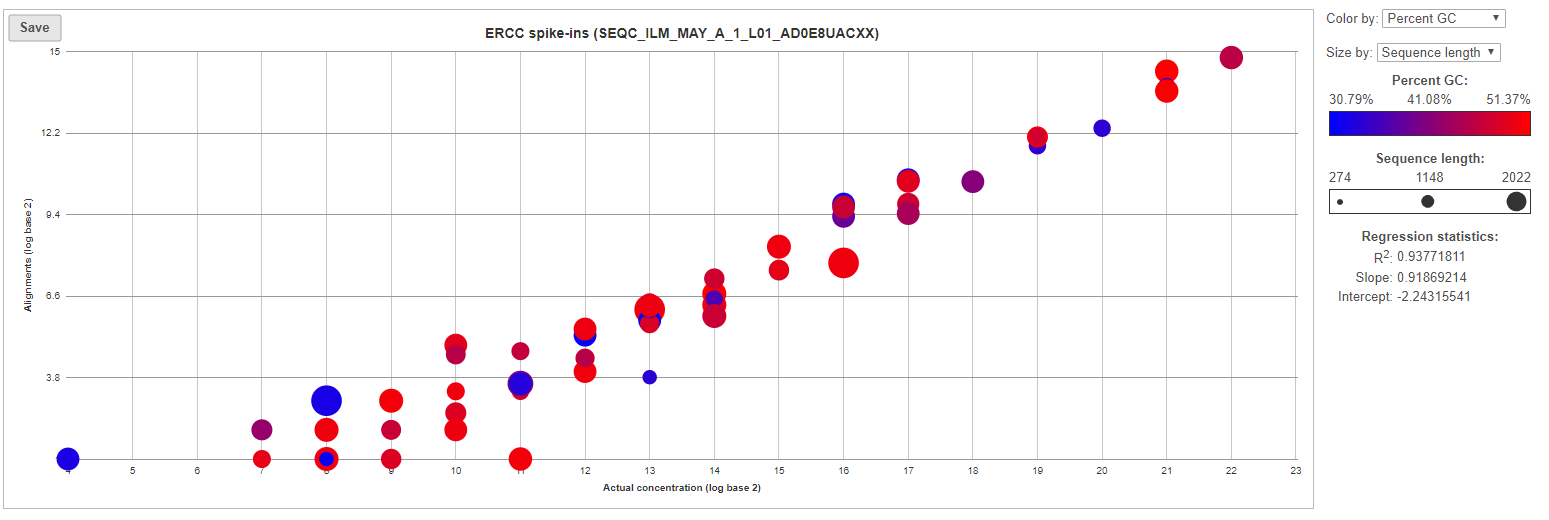
Figure 6. Scatter plot of actual observed alignment counts vs. probe concentration for each ERCC control within a sample. Each dot is an ERCC control, coloured by GC content and sized by concentration
The table (Figure 7) lists individual controls, with their actual concentration, alignment counts, sequence length, and % GC content. The table can be downloaded to the local computer by selecting the Download link.
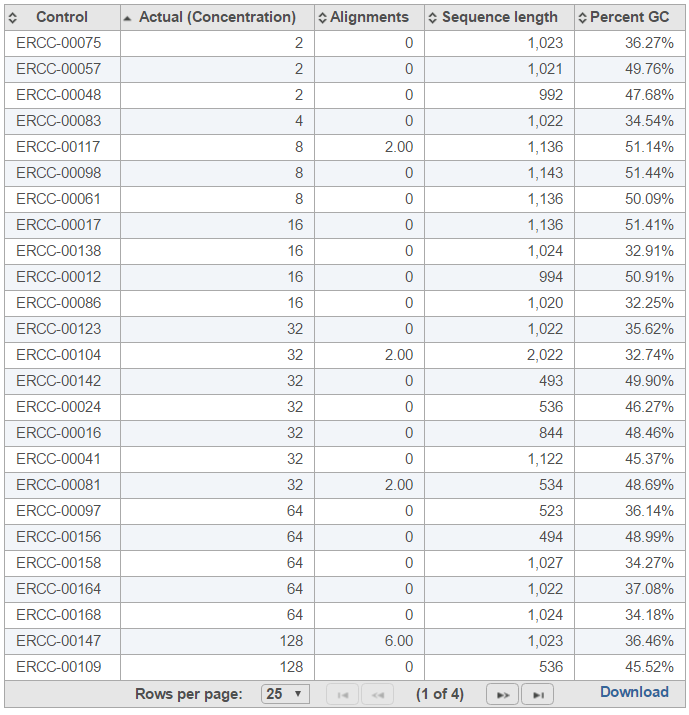
Figure 7. Table report for ERCC controls within a sample. The default sort order is by column Control; the example in the figure is sorted by Actual (Concentration) to highlight the relationship between the control concentration and number of alignments
For more details on ExFold comparisons, select a comparison name in the ExFold summary table (Figure 8). First, you will get a comprehensive scatter plot of observed Mix1:Mix2 ratios (y-axis, in log2 space) vs. the expected Mix1:Mix2 ratio (x-axis, in log2 space). Each dot on the plot represents an ERCC sequence, coloured based on GC content and sized by sequence length (plot controls are on the right).
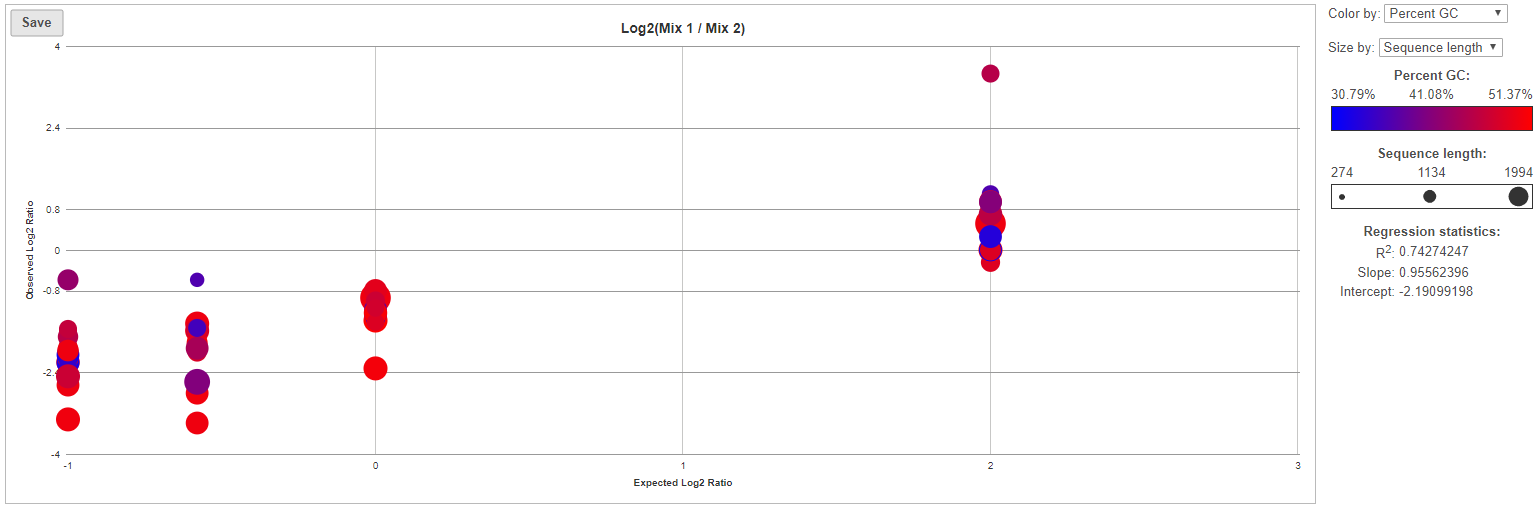 Figure 8. Scatter plot of actual observed Mix1:Mix2 ratios vs. expected Mix1: Mix2 ratios for each ERCC control within a sample. Each dot is an ERCC control, coloured by GC content and sized by concentration
The table (Figure 9) lists individual controls, with each samples' alignment counts, together with the observed and expected Mix1:Mix2 ratios. The table can be downloaded to the local computer by selecting the Download link.
Figure 8. Scatter plot of actual observed Mix1:Mix2 ratios vs. expected Mix1: Mix2 ratios for each ERCC control within a sample. Each dot is an ERCC control, coloured by GC content and sized by concentration
The table (Figure 9) lists individual controls, with each samples' alignment counts, together with the observed and expected Mix1:Mix2 ratios. The table can be downloaded to the local computer by selecting the Download link.
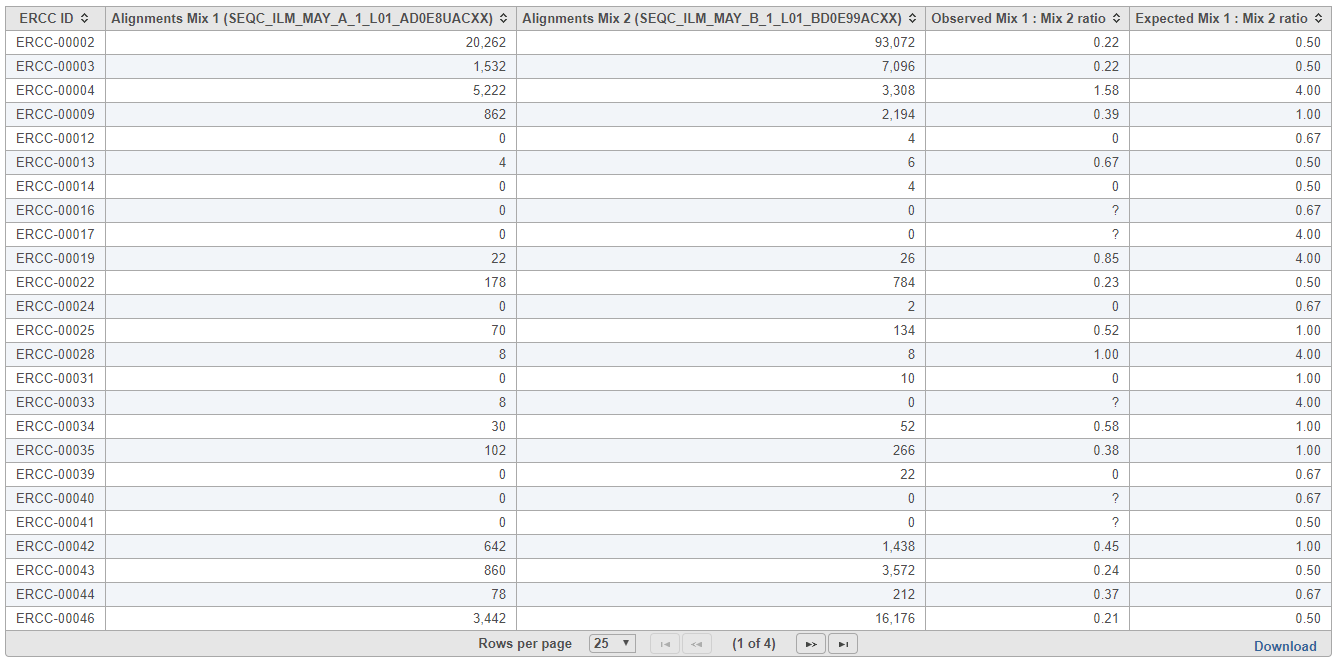 Figure 9. Table report for ERCC ExFold comparison within a sample
Figure 9. Table report for ERCC ExFold comparison within a sample
Additional Assistance
If you need additional assistance, please visit our support page to submit a help ticket or find phone numbers for regional support.


| Your Rating: |
|
Results: |

|
43 | rates |
Overview
Content Tools
1 Comment
Melissa del Rosario
author: ilukic