Page History
...
- The file contains numeric values in a table tab-delimited format, samples can be on rows (features are on columns) or columns (features are on rows)while features (e.g.gene names) are in columns, or vice versa
- The file contains unique sample ID IDs and feature IDIDs
- If there are the data contains sample attribute information, all the information these attributes have to be at the beginning of the table, the left most ether
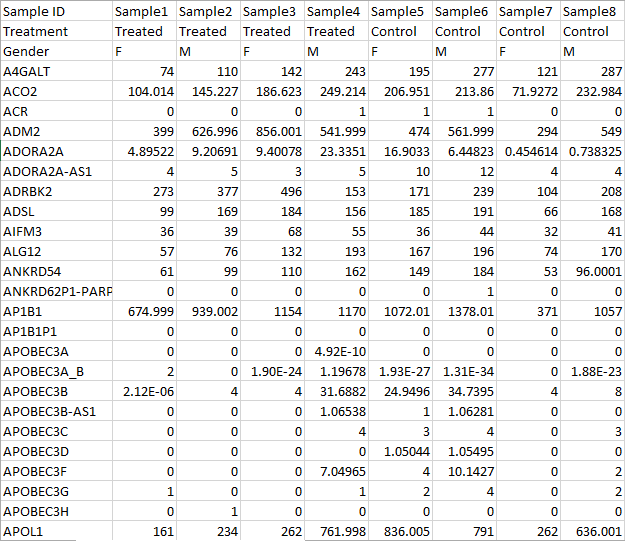
- The leftmost columns when samples are on rows (Figure 8)
- The first few rows when samples are on columns (Figure 9)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
 |
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
 |
...
Figure 9 is showing an example text file contains samples on rows, the first column is sample ID, sample attributes are in column 2 and column 3. Gene count starts from column 4 with gene ID in row one. The gene ID is compatible with the hg19 RefSeq transcript Transcripts - 2016-08-01 annotation model.
If the data has been log transformed, specify the base under Counts format.
...
Overview
Content Tools