Page History
...
Cell Ranger is a set of analysis pipelines that process Chromium single cell data to align reads, generate feature-barcode matrices, and perform clustering and gene expression analysis analysis for 10X Genomics Chromium Technology[1].
...
Cell Ranger - ATAC task in Partek® Flow® includes two different wrappers. To deal with the single cell ATAC-seq Seq dataset, the 'cellranger-atac count' pipeline from Cell Ranger ATAC v2.0[2] has been wrapped in Flow®. It takes FASTQ files from 'cellranger-atac mkfastq' and performs ATAC analysis including reads filtering and alignment, barcode counting, identification of transposase cut sites, peak and cell calling, and count matrix generation. Its outputs then become the starting point for downstream analysis for scATAC-seq Seq data in Flow. To process Chromium Single Cell Multiome ATAC + Gene Expression sequencing data, ‘cellranger-arc count’ v2.0[3] has been wrapped to generate a variety of analyses pertaining to gene expression, chromatin accessibility and their linkage.
...
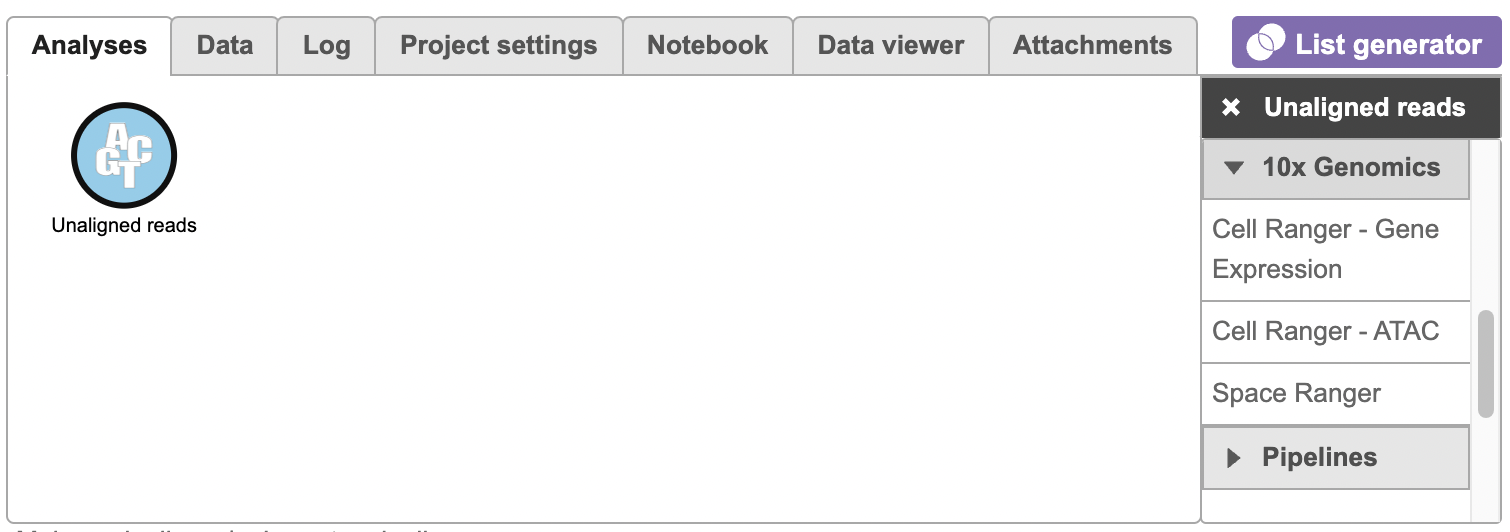
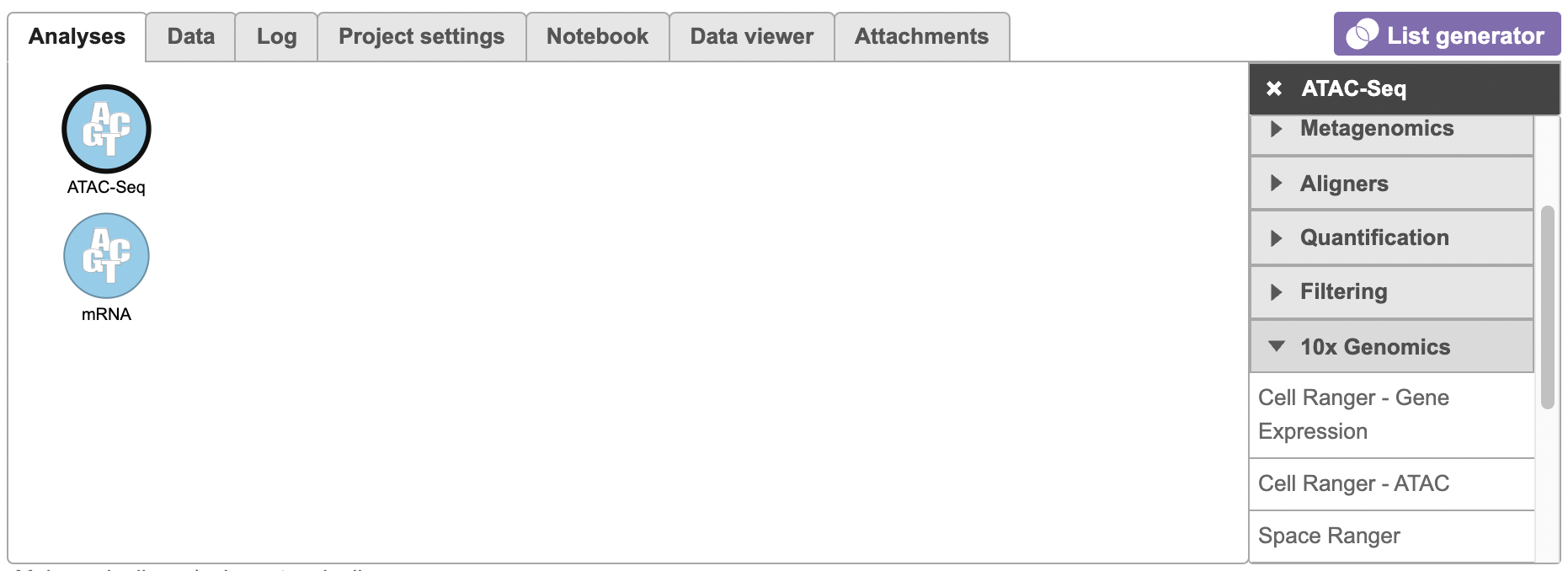
To run the Cell Ranger - ATAC task for scATAC-seq Seq data in Flow, select the Unaligned reads datanode data node, then select Cell Ranger - ATAC in the 10x Genomics section (left panel, Figure 1). For 10x multiome ATAC + Gene Expression data, there will be two data nodes once the FASTQ files have been imported into Flow properly - ATAC-Seq and mRNA (right panel, Figure 1). Users should select the ATAC-Seq datanode to trigger the Cell ranger - ATAC task.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
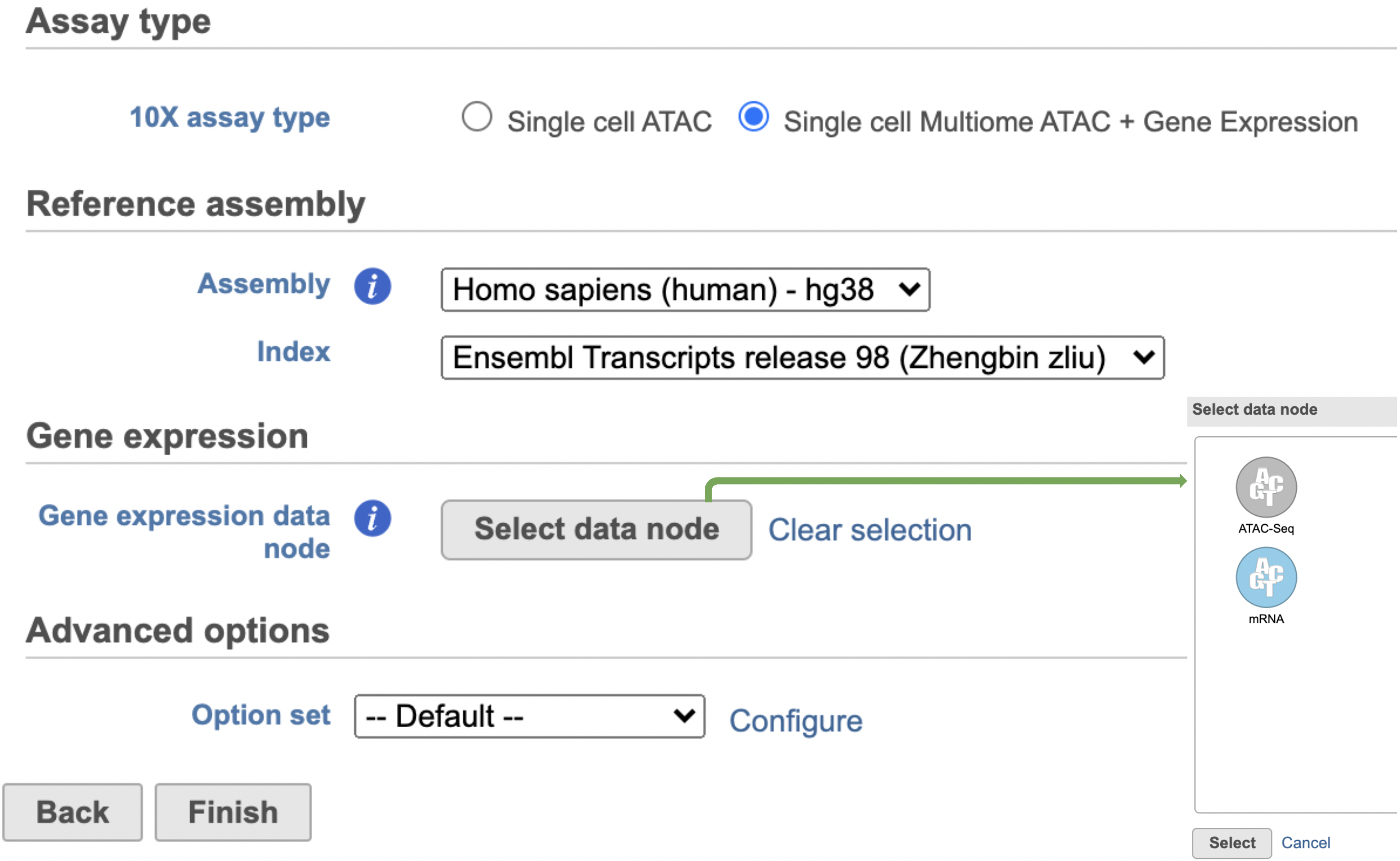
Similar to the Cell Ranger - Gene Expression task, the a first time user will be asked to create a Reference assembly. In Partek® Flow®, we will use Cell Ranger ARC 2.0.0 to create reference a Reference assembly for all 10x Genomics analysis pipelines. Please refer to our Cell Ranger - Gene Expression task manual on how to build or use Reference assembly.
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
A After the task has finished successfully, a new data node named Single cell counts will be displayed in Flow if the task has been finished successfully (Figure 4). This data node contains a filtered peak barcode count matrix for ATAC-Seq data, but a unified feature-barcode matrix that contains gene expression counts alongside ATAC-Seq peak counts for each cell barcode for multiomic data. To open the task report when the task is finished, double click the output data node, or select the Task report in the Task results section after single clicking the data node. Users then will find the The task report (Figure 5) is the same as the ‘Summary HTML’ from Cell Ranger ATAC output.
...
Cell Ranger - ATAC task report in Flow
Task The task report is sample based. Users can use the dropdown list on the top left to switch samples. Under the sample name, there are two tabs on each report - Summary report and Data Quality report (Figure 5). Important information on the Estimated Number of Cells, Median high-quality fragments per cell, Fraction of high-quality fragments overlapping peaks, as well as information on Sample, Sequencing, Cells and Cell Clustering are summarized in different panels. The Importantly, the Barcode Rank plot and the Fragment Distribution plot have also been included as an important piece in the Cells section in of the Summary report (Figure 5). Descriptions of metrics in the following sections can also be found by clicking the ![]() to the section header in the Summary HTML file itself.
to the section header in the Summary HTML file itself.
...
The Library Complexity section in Data Quality report plots the observed per cell complexity, measured as median unique fragments per cell, as a function of mean reads per cell. (Figure 6). While the Mapping section displays the Insert Size Distribution plot, and metrics derived from it. Single Cell ATAC read pairs produce detailed information about nucleosome packing and positioning. The fragment length distribution captures the nucleosome positioning periodicity. The Targeting section shows profiling of the chromatin accessibility behavior of the library at epigenetically relevant regions in the genome. The Enrichment around TSS plot is helpful to assess the signal-to-noise ratio of the library. It is well known that Transcriptional Start Sites (TSSs) and the promoter regions around them have a higher degree of chromatin accessibility compared to the other regions of the genome. The Peaks targeting plot presents the variation in the number of on-target fragments, or fragments that overlap peaks, within each barcode group. A higher percentage of the barcode fragments overlap peaks is expected for cell-associated barcodes.
...
The task report for multiomic data analysis is much more complicated. It contains summary metrics at different levels - ATAC, gene expression, both/joint. Joint view is the default view visible upon first rendering the summary and can be accessed by clicking "Joint" at the top left corner. Metrics that are specific to the given Chromatin Accessibility library will appear in the ATAC tab. Lastly, metrics that are specific to the given gene expression library will appear in the Gene Expression tab (Figure 7). To understand the details, please refer to 10x Genomics webpage[4].
...
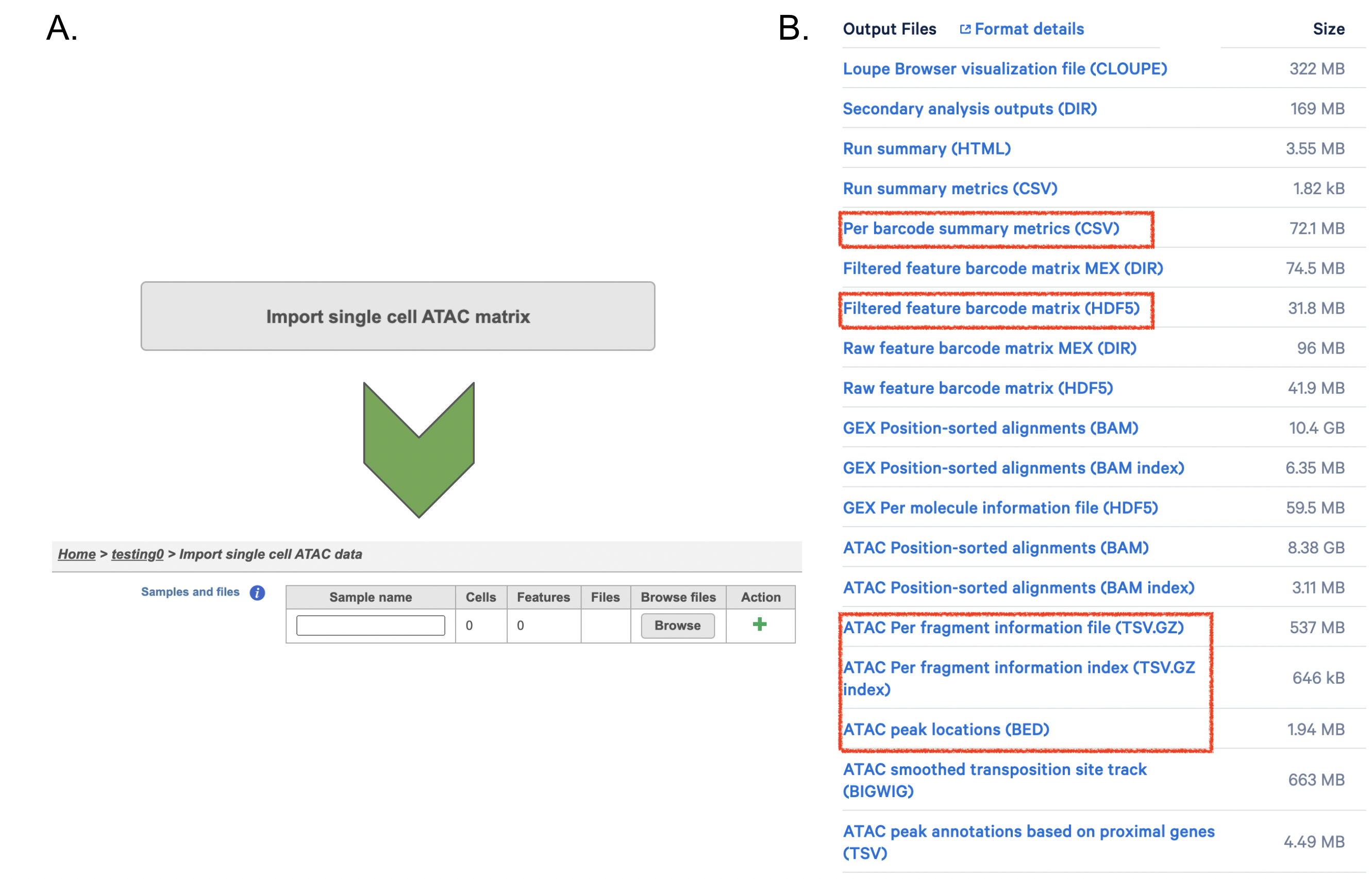
If users have converted FASTQ outside of Partek, Flow has the importer available for count matrix can be imported along with additional files (Figure 8A). Files that Flow will need to complete the import includes the followingsfollowing:
filtered_feature_bc_matrix.h5
...
fragments.tsv.gz.
Those five files can usually could be found in the outs/ subdirectory within the pipeline output directory (Figure 8B). Five files are necessary per sample because scATAC-seq is more complicated , unlike than RNA-seq - if . If peak calling was performed on each sample/dataset independently, the peaks are unlikely to be exactly the same . We therefore so all of the samples/datasets need to be merged to create a common set of peaks across all the samples/datasets to be merged. The datasets combination in Flow ; this is performed during data import - therefore it needs all wherein all of the samples/datasets need to be imported at one time, not separately. To add samples, Please click the green + button to add more samples (Figure8A).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
...
Overview
Content Tools