Page History
...
- Open Partek Genomics Suite, choose File>Open.. from the main menu to open the Training.fmt.
- Select Tools > Predict > Model Selection from the Partek main menu
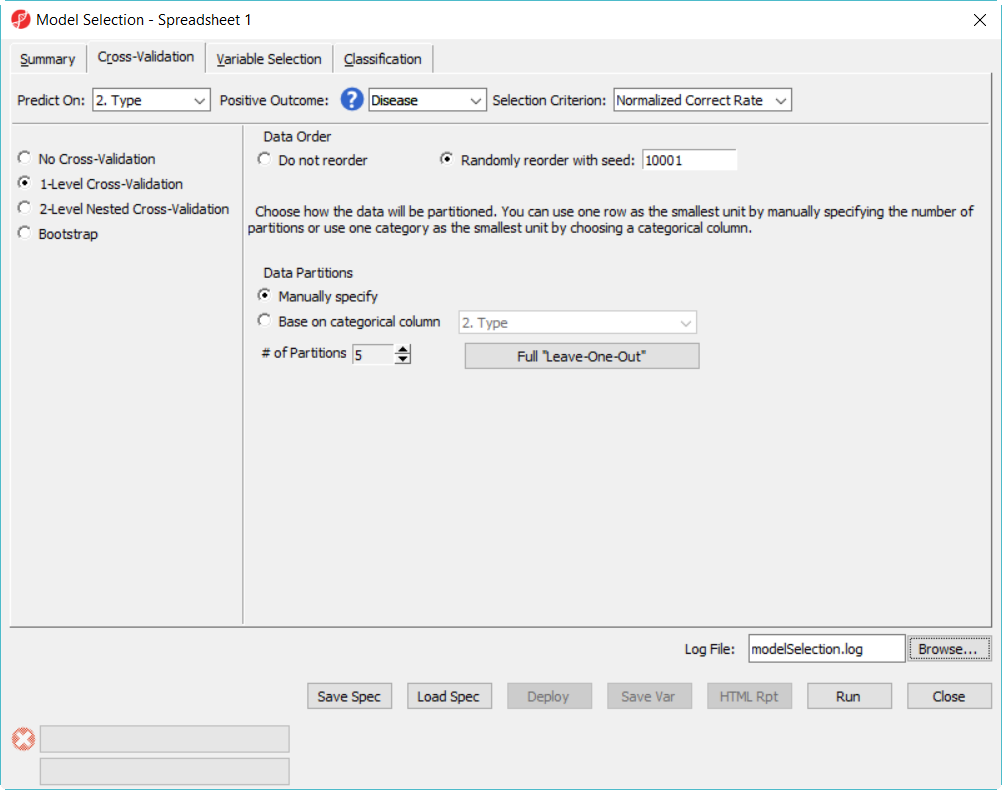
- In Cross-Validation tab, choose to Predict onType, Positive Outcome is Disease, Selection Criterion is Normalized Correct Rate (Figure 1)
- Choose 1-Level Cross-Validation option, and use Manually specify partition option as 5– use 1-level cross validation option is to select the best model to deploy
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
...
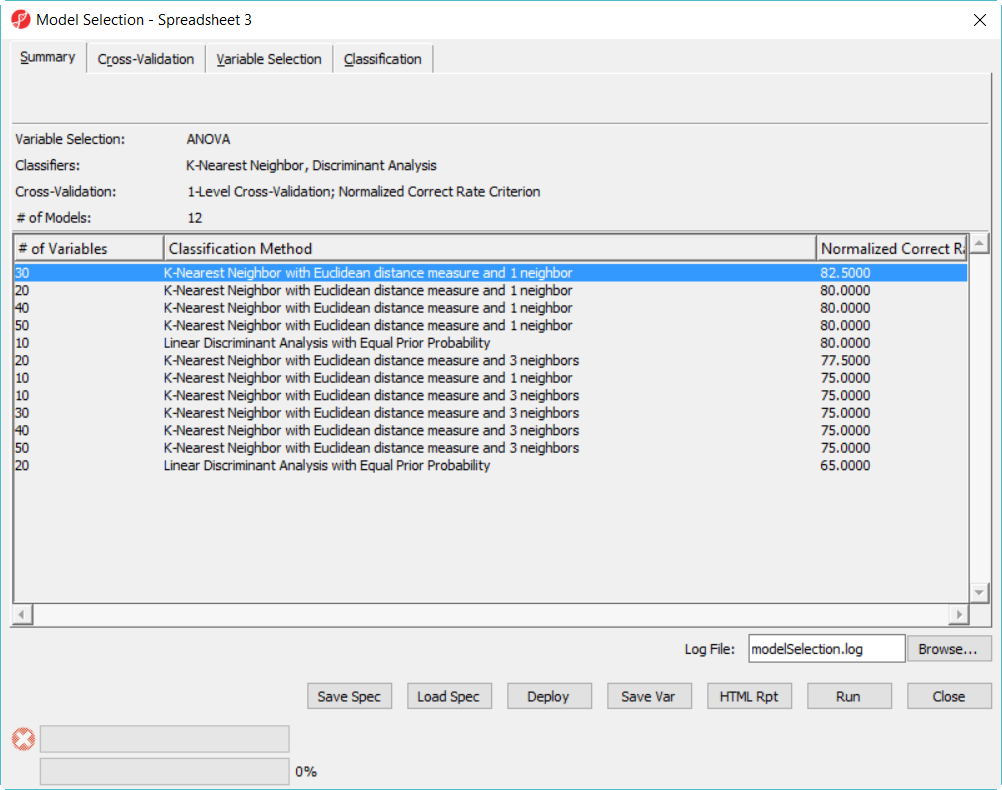
The best model is 30 variables using 1-Nearest Neighbor with Euclidean distance measure (Figure 8)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
...
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
Cross-validation
Cross validation is used to esimate the accuracy of the predictive model, it is the solution to overfitting problem. One example of ovefitting is testing the model on the same data set when the model is trained. It is like to give sample questions to students to practice before exam, and the exact same questions are given to the students during exam, so the result is biased.
Common mistakes
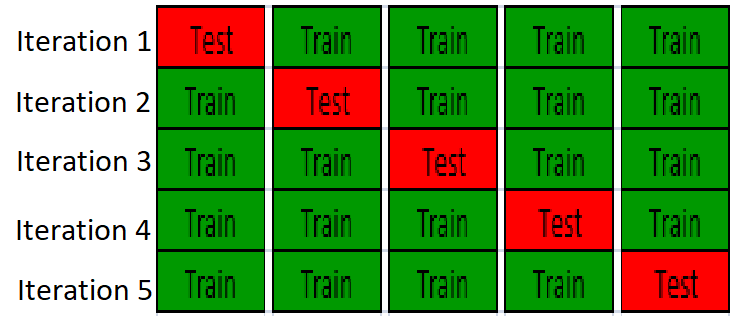
In cross-validation, the data is partition the data into training set and test set, build a model on training set and validate the model on the test set, so test set is completely independing from model traininig. An example of K-fold cross-validation is to randomly divide the whole data into k equal sized subsets, take one subset as test set, use the remanining k-1 subset to training a model, it will repeat k times, so all the samples are used for both training and test, and each sample is tested once. The following figure is showing 5-fold cross-validation:
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
Common mistakes
In Partek model selection tool, the cross-validation is performed first. Each iteration of cross-valiation, the variable selection and classification are performed on the training set, and the test set is completely independent to validate the model. One common mistake is to select variable beforehand, e.g. using perform ANOVA on the whole dataset and use ANOVA's result to select top genes, and perform the cross-valiation to get correct rate. In this case, the test sets in cross validation were used in the variable selection, it is not independend from the training set, so the result will be biased.
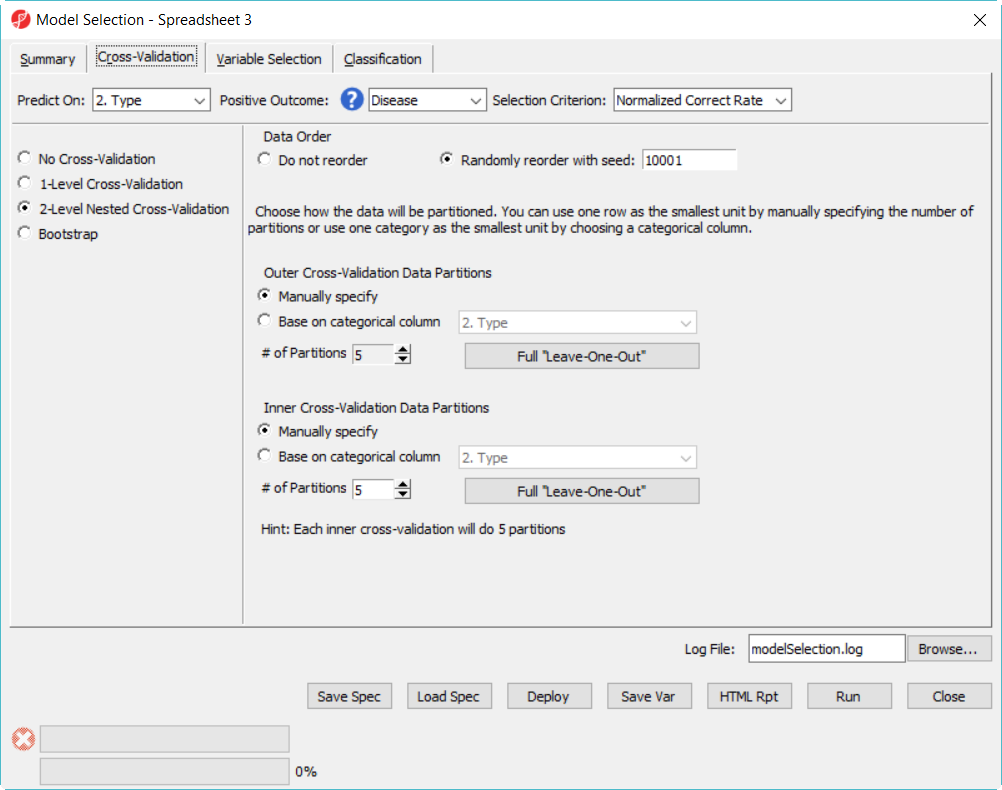
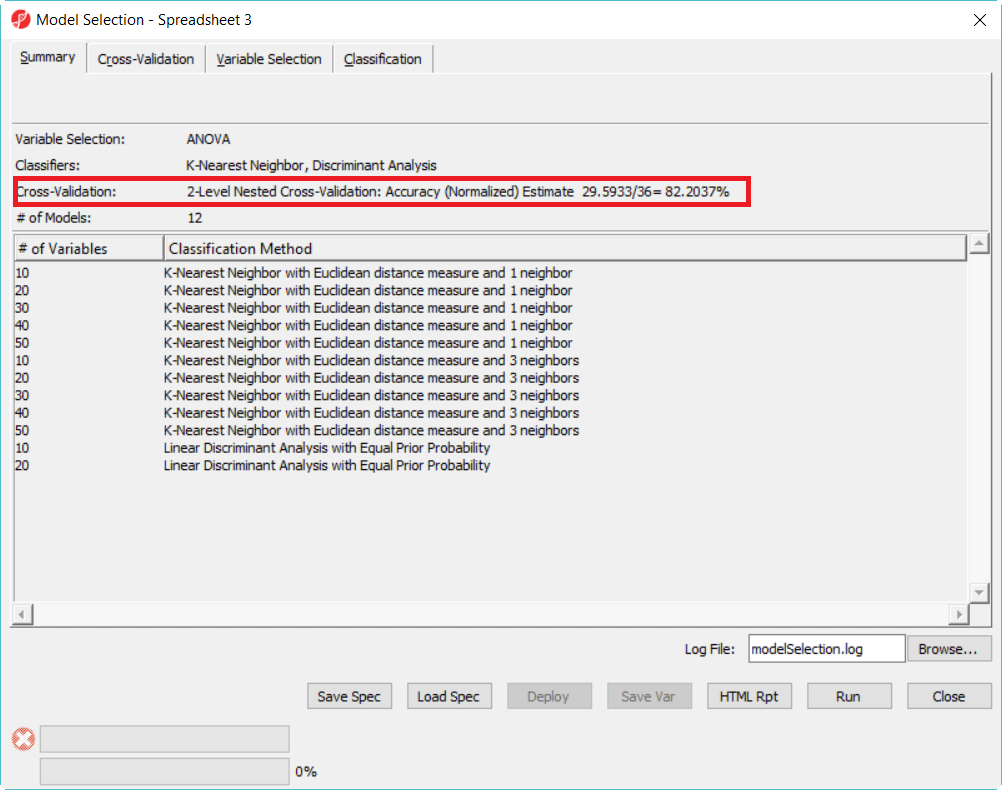
Another common mistake is to run 1-level cross-validation with multiple models, and report the correct rate of the best model as the deployed model correct rate. The reason is that in 1-level cross validation, the test set is used to select the best model, it can't be used to get accuracy estimate since it is not independent anymore. So either use 2-level cross-validation option or use another independ set to get the accuracy estimate. Below is an example to demostrate this concept:
| Additional assistance |
|---|
|
| Rate Macro | ||
|---|---|---|
|
Overview
Content Tools