Page History
| Table of Contents | ||||||
|---|---|---|---|---|---|---|
|
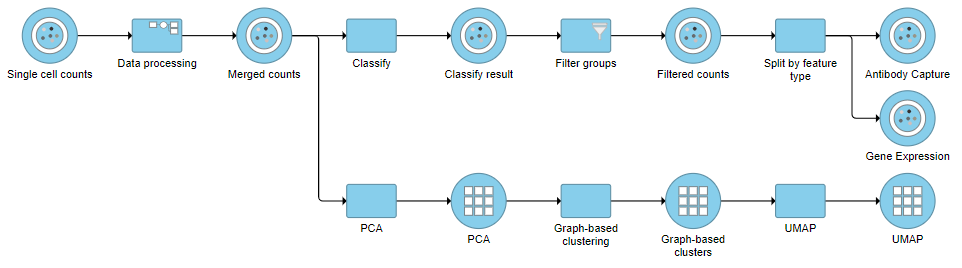
Next, we will filter out certain cells and re-split the data. Re-splitting the data can be useful if you want to perform differential analysis and downstream analysis separately for proteins and genes. For your own analyses, re-splitting the data is optional. You could just as well continue with differential analysis with the merged data if you prefer.
Filter Groups
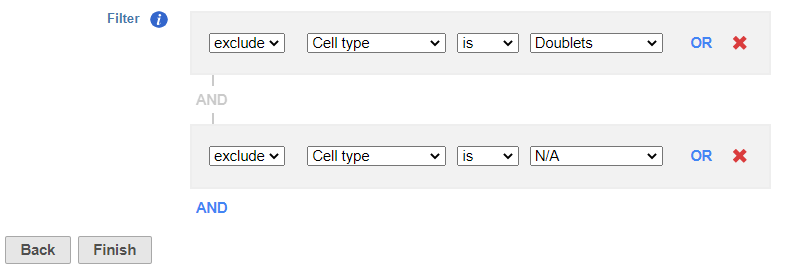
Because we have classified our cells, we can now filter based on those classifications. This can be used to focus on a single cell type for re-clustering and sub-classification or to exclude cells that are not of interest for downstream analysis.
- Click the Classified result data node
- Click Filtering
- Click Filter groups
- Set to exclude Cell type is Doublets using the drop-down menus
- Click AND
- Set the second filter to exclude Cell type is N/A using the drop-down menus
- Click Finish to apply the filter (Figure 1)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
This produces a Filtered counts data node (Figure 2).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

Re-split the Matrix
- Click the Filtered counts data node
- Click Pre-analysis tools
- Click Split by feature type
This will produce two data nodes, one for each data type (Figure 3). The split data nodes will both retain cell classification information.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
Differential Analysis and Visualization - Protein Data
Once we have classified our cells, we can use this information to perform comparisons between cell types or between experimental groups for a cell type. In this project, we only have a single sample, so we will compare cell types.
- Click the Antibody Capture data node
- Click Differential analysis
- Click GSA
The first step is to choose which attributes we want to consider in the statistical test.
- Check Cell type to include it in the statistical test
- Click Next
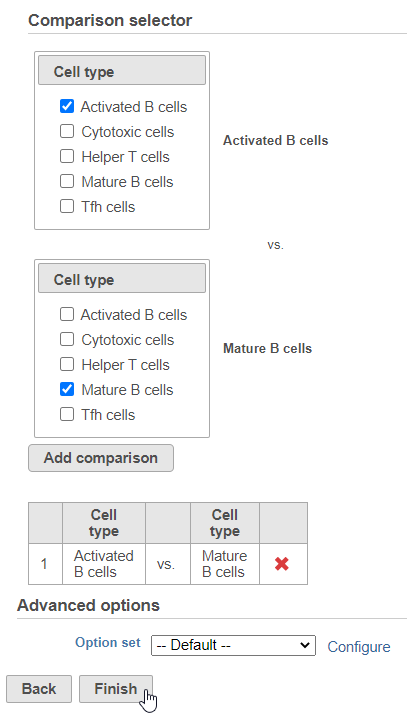
Next, we will set up the comparison we want to make. Here, we will compare the Activated and Mature B cells.
- Check Activated B cells in the top panel
- Check Mature B cells in the bottom panel
- Click Add comparison
The comparison should appear in the table as Activated B cells vs. Mature B cells.
- Click Finish to run the statistical test (Figure 4)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
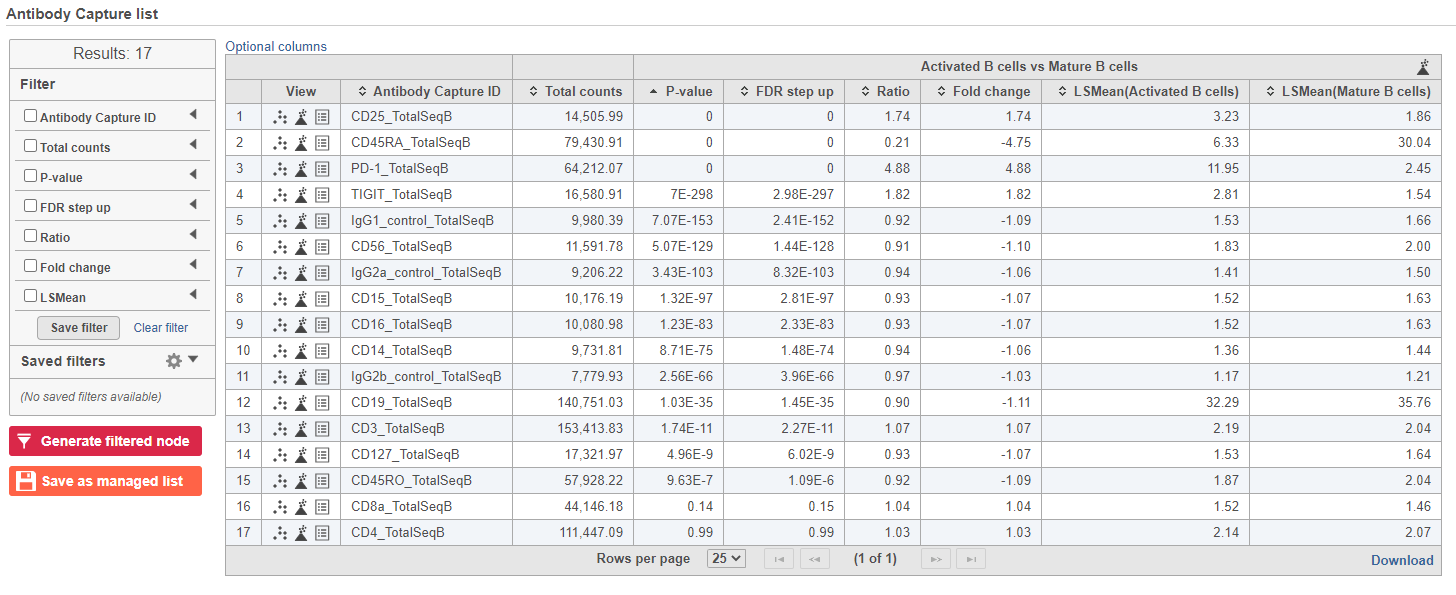
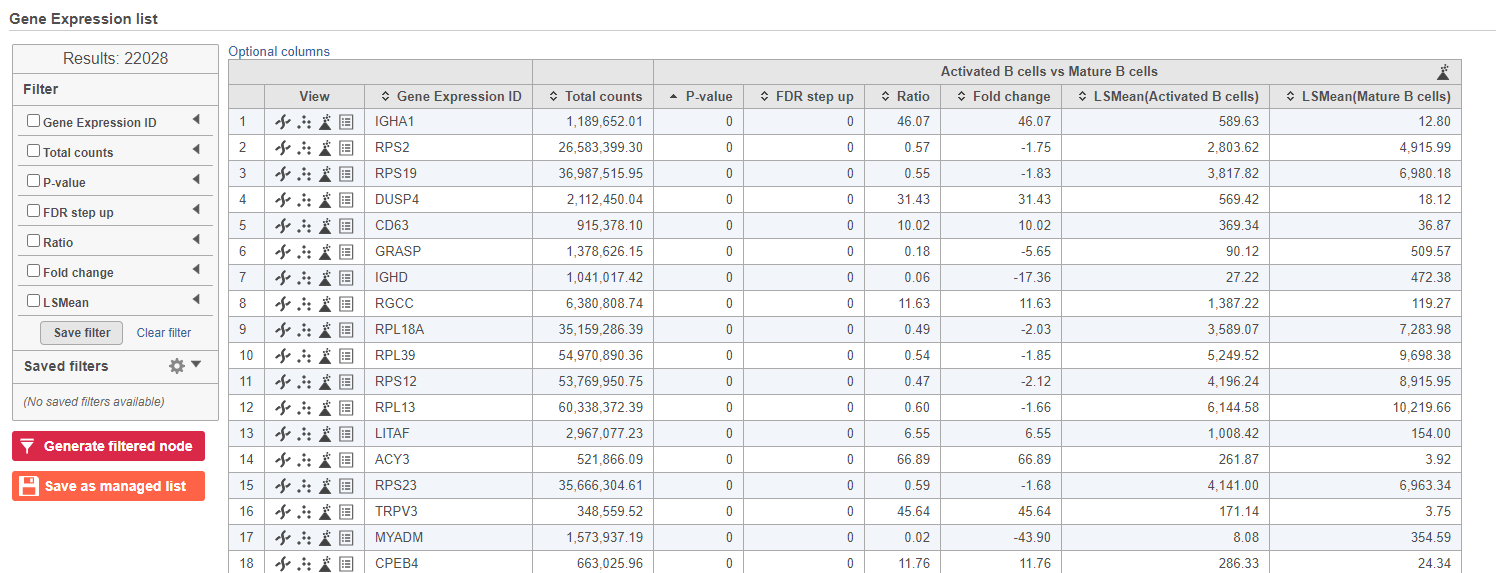
The GSA task produces a GSA data node.
- Double-click the GSA data node to open the task report
The report lists each feature tested, giving p-value, false discovery rate adjusted p-value (FDR step up), and fold change values for each comparison (Figure 5).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
In addition to the listed information, we can access dot and violin plots for each gene or protein from this table.
- Click
 in the CD45RA_TotalSeqB row
in the CD45RA_TotalSeqB row
This opens a dot plot in a new data viewer session, showing CD45A expression for cells in each of the classifications (Figure 6).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
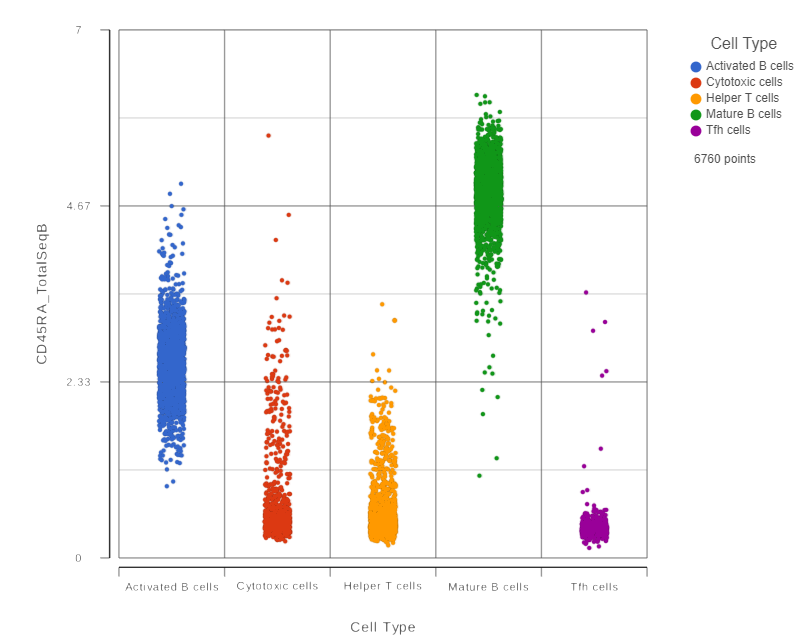
We can use the Configuration panel on the left to edit this plot.
- Expand the Summary card
- Switch on Violins
- Switch on Overlay
- Switch on Colored
- Expand the Data card
- Use the slider to increase the Jitter
- Expand the Color card
- Use the slider to decrease the Opacity (Figure 7)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

- Click the project name to return to the Analyses tab
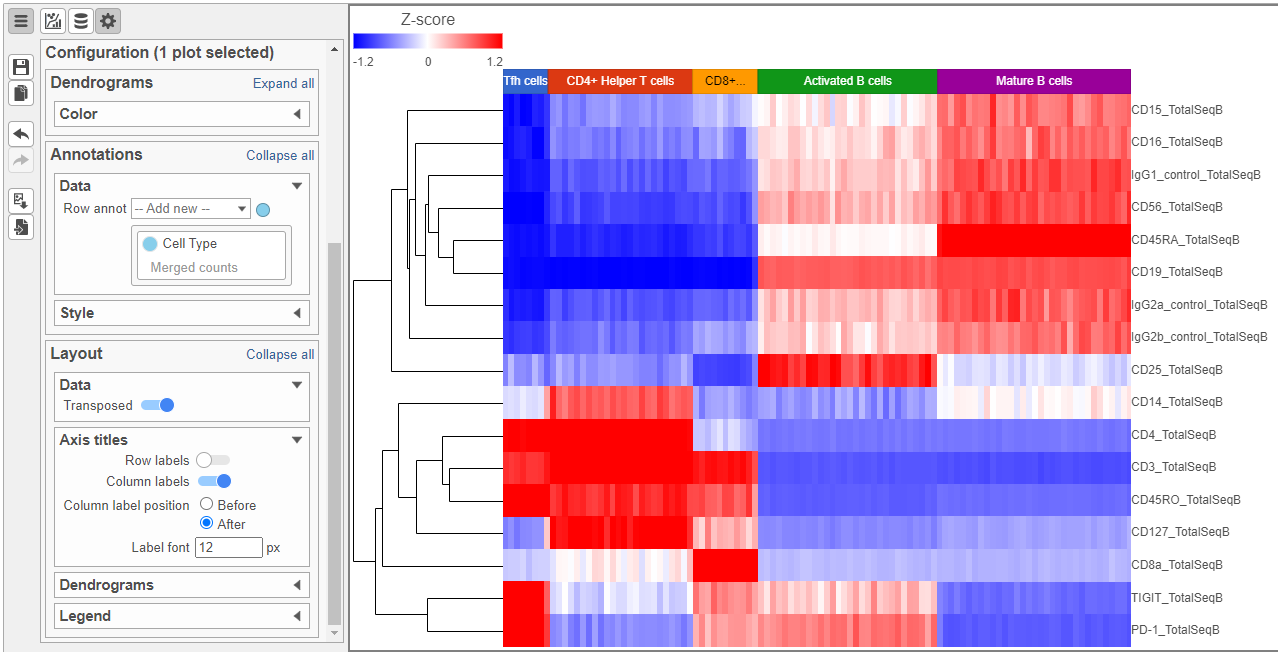
To visualize all of the proteins at the same time, we can make a hierarchical clustering heat map.
- Click the GSA data node
- Click Exploratory analysis in the toolbox
- Click Hierarchical clustering/heat map
- In the Ordering section, choose Cell type from the Sample order drop-down list
- Click Finish to run with the other default settings
- Double-click the Hierarchical clustering task node to open the heat map (Figure 8)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
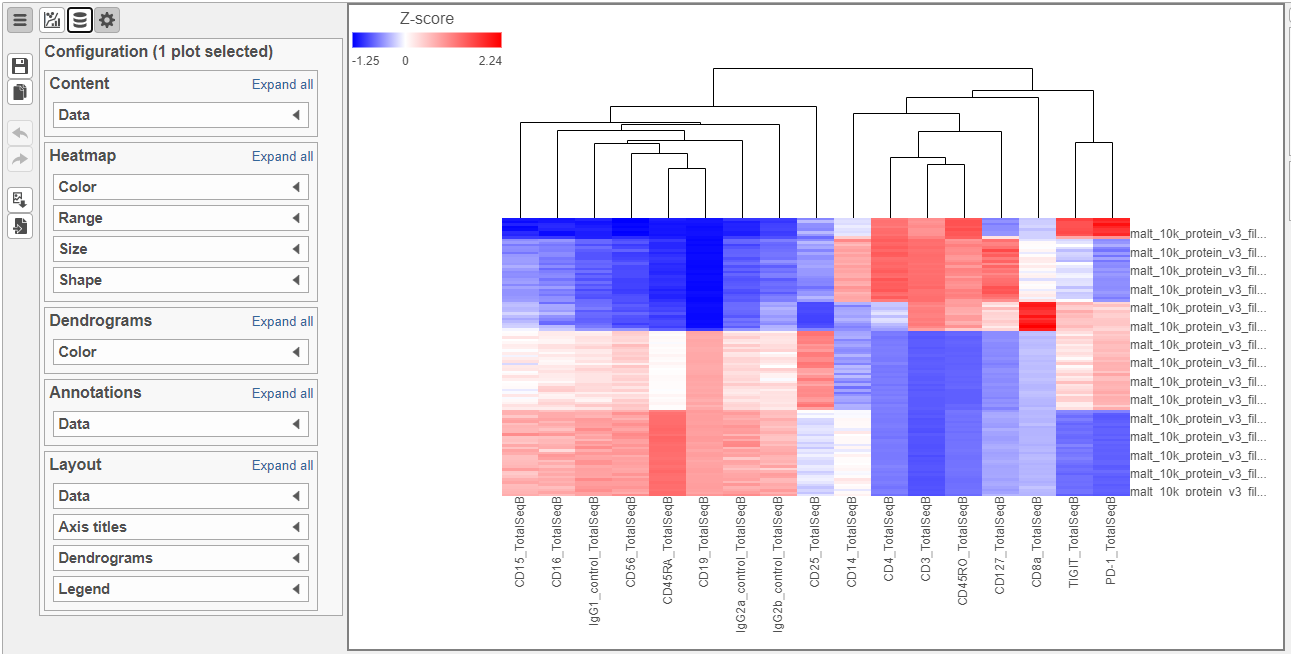
The heat map can easily be customized using the Configuration card on the left.
- In the Layout section, expand the Axis titles card
- Disable the Row labels
- Activate the Transpose switch (Figure 9)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
- In the Annotations section, expand the Data card
- Click the grey circle and choose Merged counts as the data source
- Choose Cell type from the drop-down menu (Figure 10)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
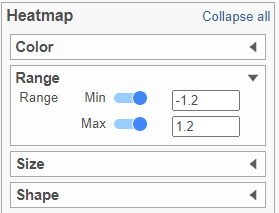
- In the Heatmap section, expand the Range card
- Set the Min and Max to -1.2 and 1.2, respectively (Figure 11)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
Feel free to explore the other options in the Configuration card on the left to customize the plot further (Figure 12).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
Differential Analysis, Visualization, and Pathway analysis - Gene Expression Data
We can use a similar approach to analyze the gene expression data.
- Click the project name to return to the Analyses tab
- Click the Gene Expression data node
- Click Differential analysis
- Click GSA
- Check Cell type to include it in the statistical test
- Click Next
- Check Activated B cells in the top panel
- Check Mature B cells in the bottom panel
- Click Add comparison
- Click Finish to run the statistical test
As before, this will generate a GSA task node and a GSA data node.
- Double-click the GSA task node to open the task report (Figure 13)
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
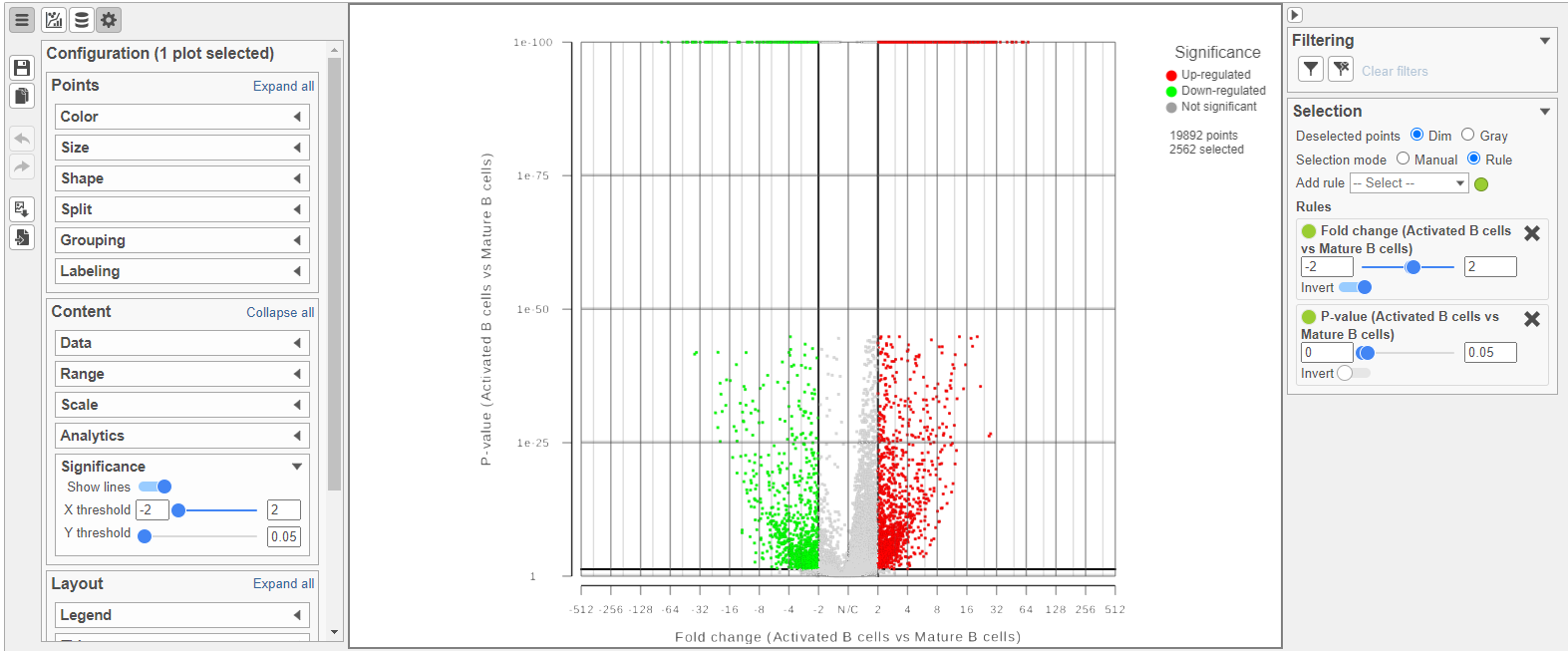
Because more than 20,000 genes have been analyzed, it is useful to use a volcano plot to get an idea about the overall changes.
- Click
 in the top right corner of the table to open a volcano plot
in the top right corner of the table to open a volcano plot
The Volcano plot opens in a new data viewer session, in a new tab in the web browser. It shows each gene as a point with cutoff lines set for P-value (y-axis) and fold-change (x-axis). By default, the P-value cutoff is set to 0.05 and the fold-change cutoff is set at |2| (Figure 14).
The plot can be configured using various options in the Configuration card on the left. For example, the Color, Size and Shape cards can be used to change the appearance of the points. The X and Y-axes can be changed in the Data card. The Significance card can be used to set different Fold-change and P-value thresholds for coloring up/down-regulated genes.
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
- Click the GSA report tab in your web browser to return to the full report
We can filter the full set of genes to include only the significantly different genes using the filter panel on the left.
- Click FDR step up
- Type 0.05 for the cutoff and press Enter on your keyboard
- Click Fold change
- Set to From -2 to 2 and press Enter on your keyboard
The number at the top of the filter will update to show the number of included genes (Figure 15).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
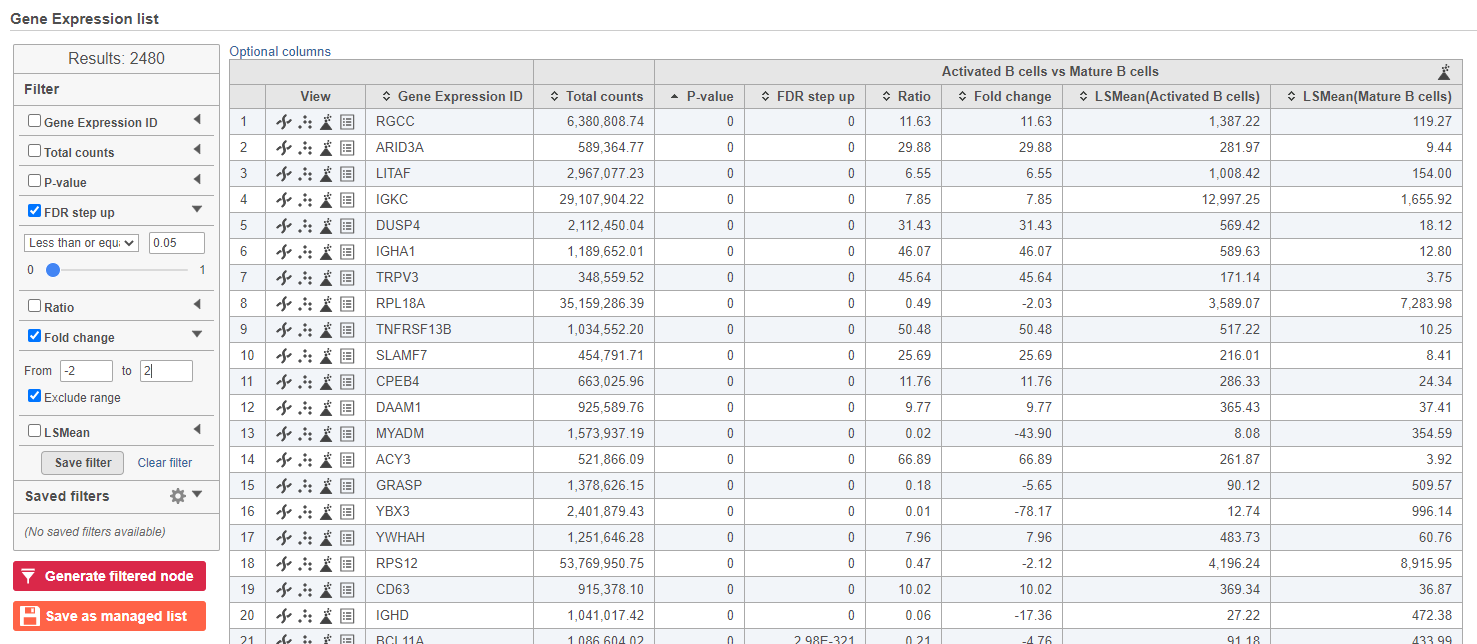
- Click
to create a new data node including only these significantly different genes
A task, Differential analysis filter, will run and generate a new Filtered Feature list data node. We can get a better idea about the biology underlying these gene expression changes using gene set or pathway enrichment. Note, you need to have the Pathway toolkit enabled to perform the next steps.
- Click the Filtered feature list data node
- Click Biological interpretation in the toolbox
- Click Pathway enrichment
- Make sure that Homo sapiens is selected in the Species drop-down menu
- Click Finish to run
- Double-click the Pathway enrichment task node to open the task report
The pathway enrichment results list KEGG pathways, giving an enrichment score and p-value for each (Figure 16).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
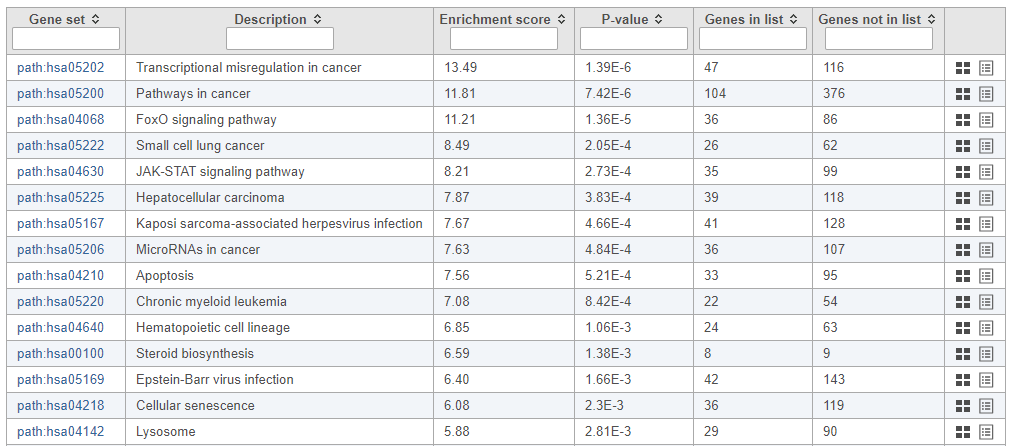
To get a better idea about the changes in each enriched pathway, we can view an interactive KEGG pathway map.
- Click path:hsa05202 in the Transcriptional misregulation in cancer row
The KEGG pathway map shows up-regulated genes from the input list in red and down-regulated genes from the input list in green (Figure 17).
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|
| Numbered figure captions | ||||
|---|---|---|---|---|
| ||||
|

| Additional assistance |
|---|
| Rate Macro | ||
|---|---|---|
|
Overview
Content Tools